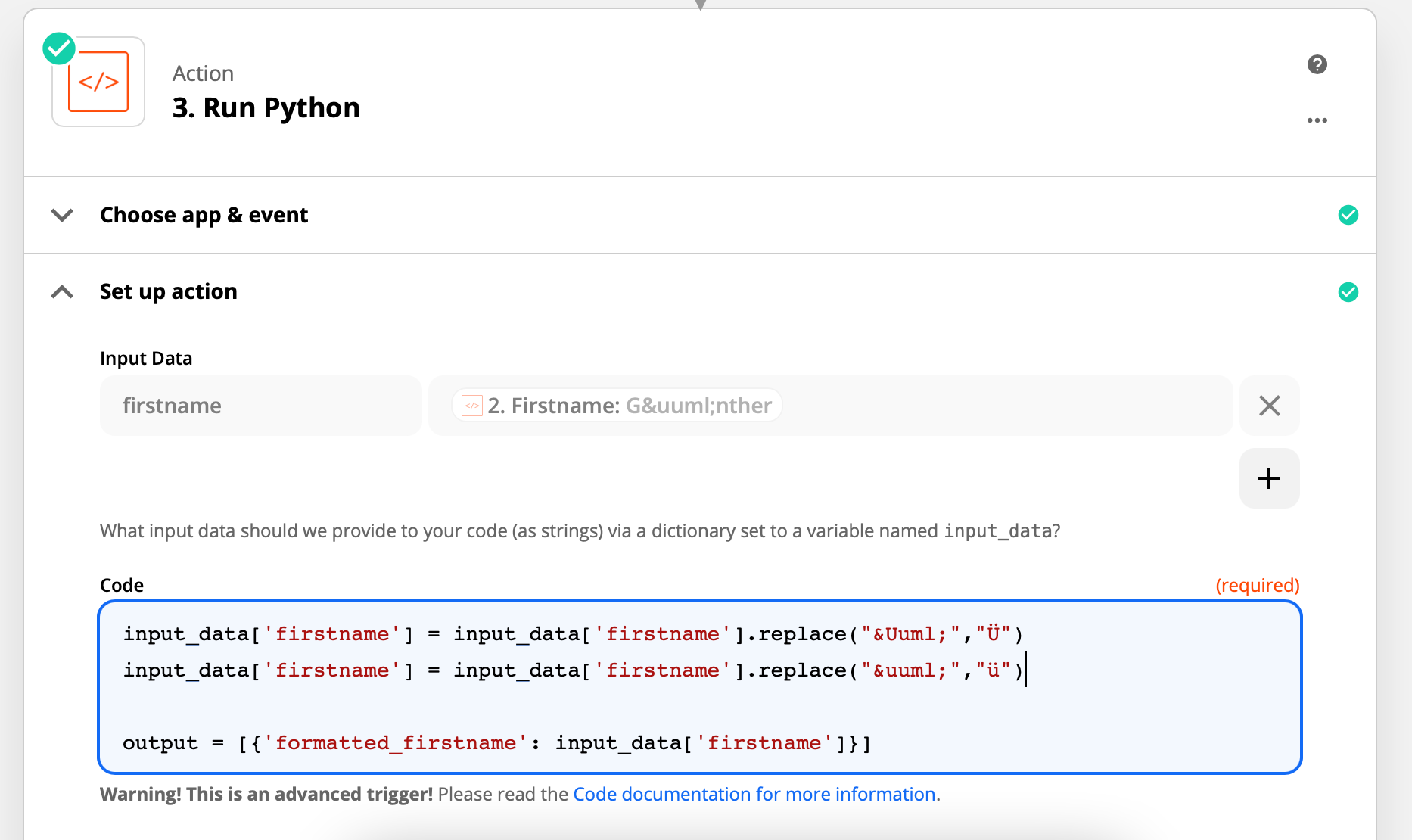
Hello, I am trying to convert text I retrieve from a invoicing tool. The text does contain the german umlauts (ä, ö, ü). And the data is formatted as HTML (i.e. ä = ä / ü = ü etc.).
I used the Zapier Format/Convert HTML to Markdown, but it does convert the umlauts not correctly: &aauml; = a / ü = u.
Is there a better way to convert HTML to text with umlauts?
Thanks :-)
Best answer by MarijnVerdult
View original