Good morning.
I have a question about using the ChatGPT integration and what it can do for me. My goal is to recreate the fine-tuning process on my own using ChatGPT, until I can take advantage of the OpenAI integration with fine-tuning.
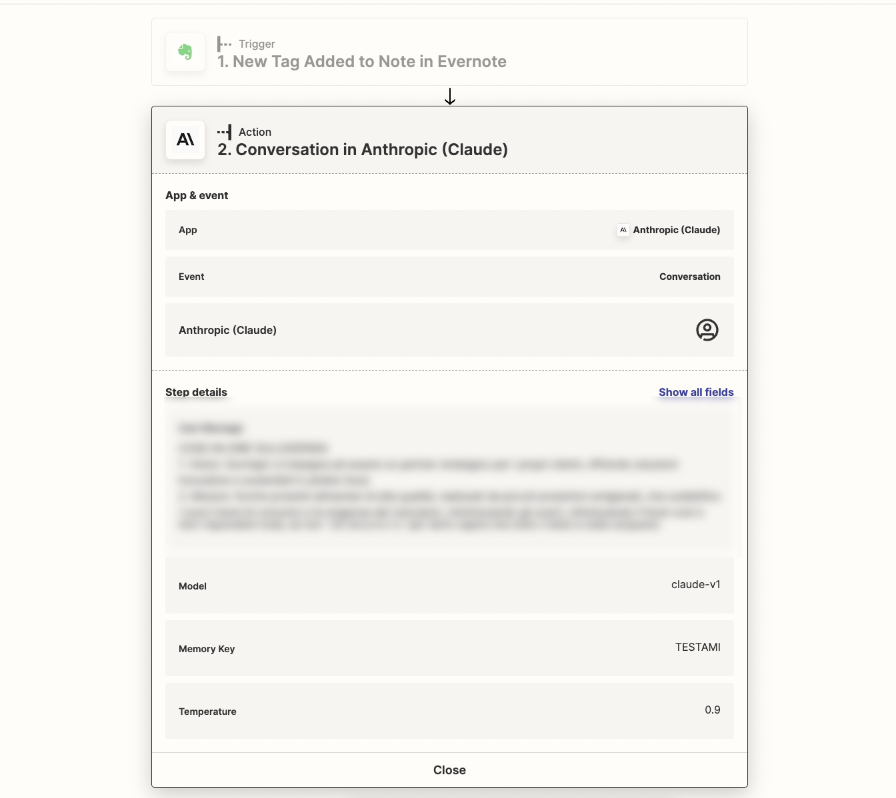
I noticed the Memory Key field in the settings and thought it might be used as constant information for ChatGPT to consider (a type of on-the-go fine-tuning). However, this isn't the case.
Here's what I need: for ChatGPT to remember a set of basic information during each step of my Zap, much like it does during live chats. This would help me obtain more precise answers. I could include this information in the prompt each time, as I'm already doing with the OpenAI integration, but this would use up tokens and fragment the request with many different prompts.
Can you tell me how I can achieve this goal? And, more importantly, could you explain the real difference between ChatGPT and OpenAI integrations?
Thank you very much for your help.


")