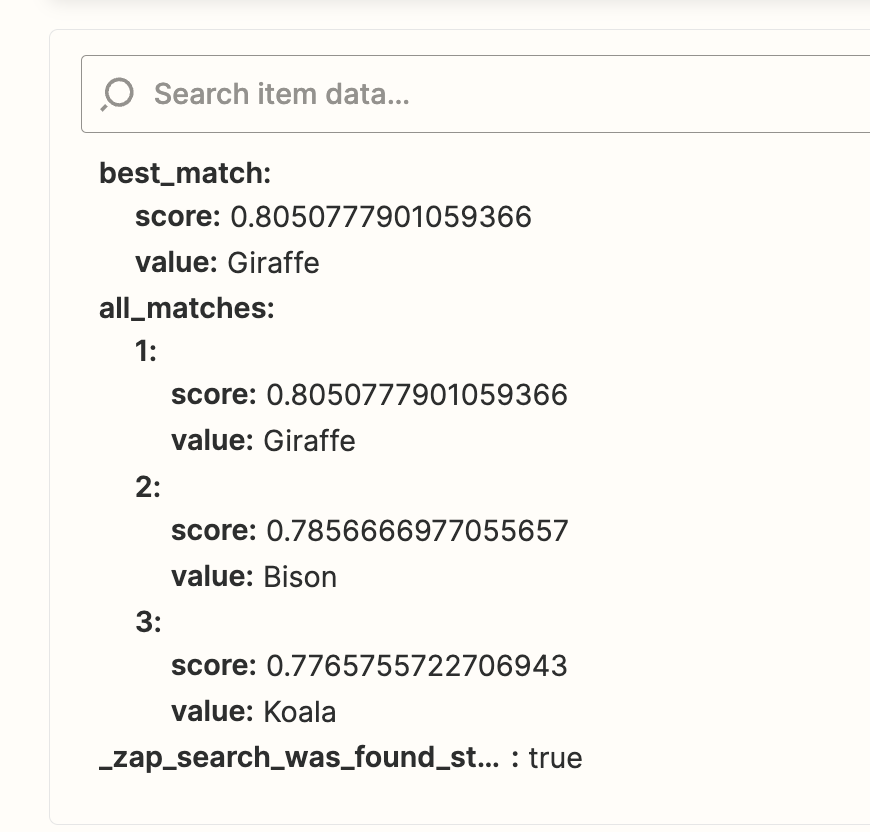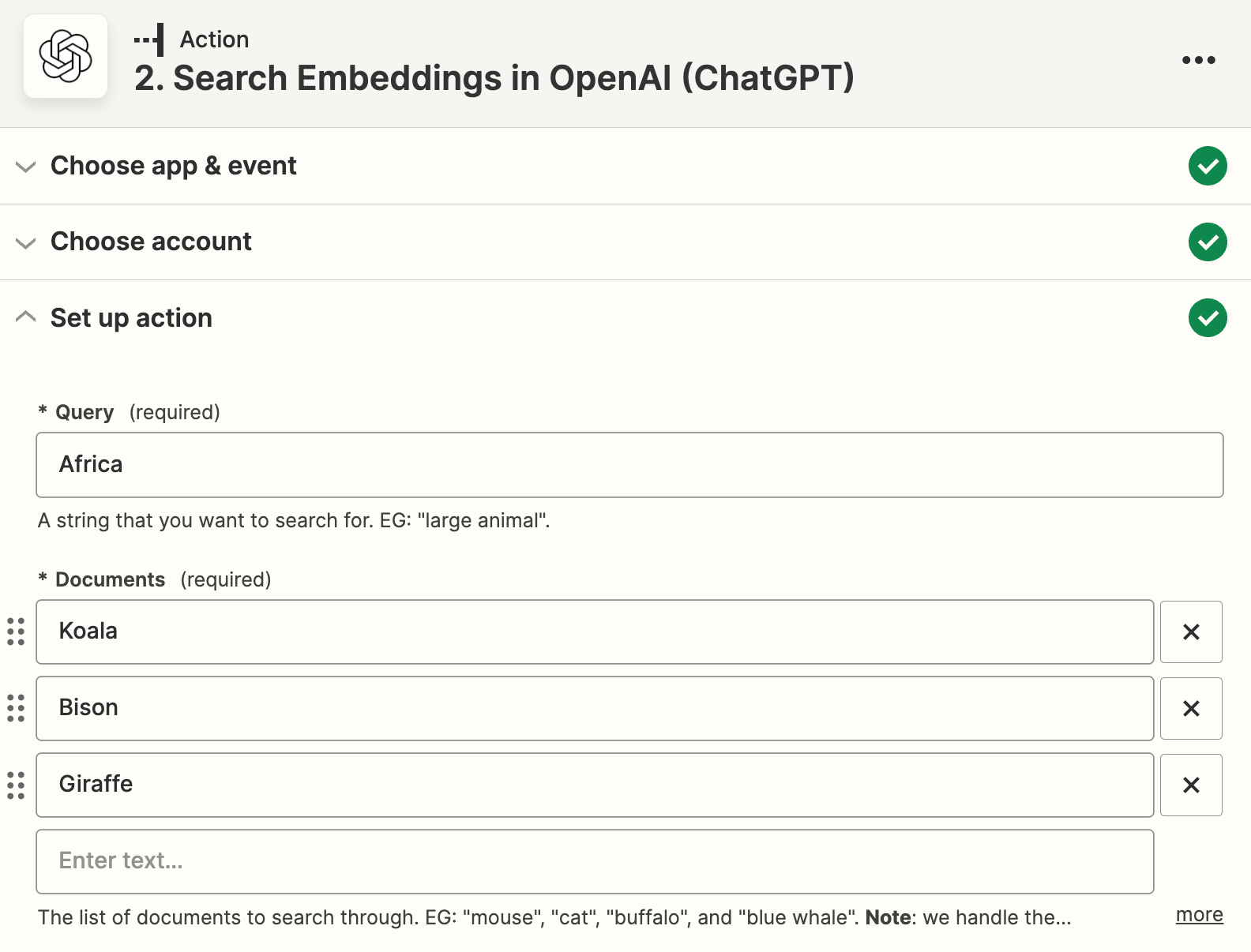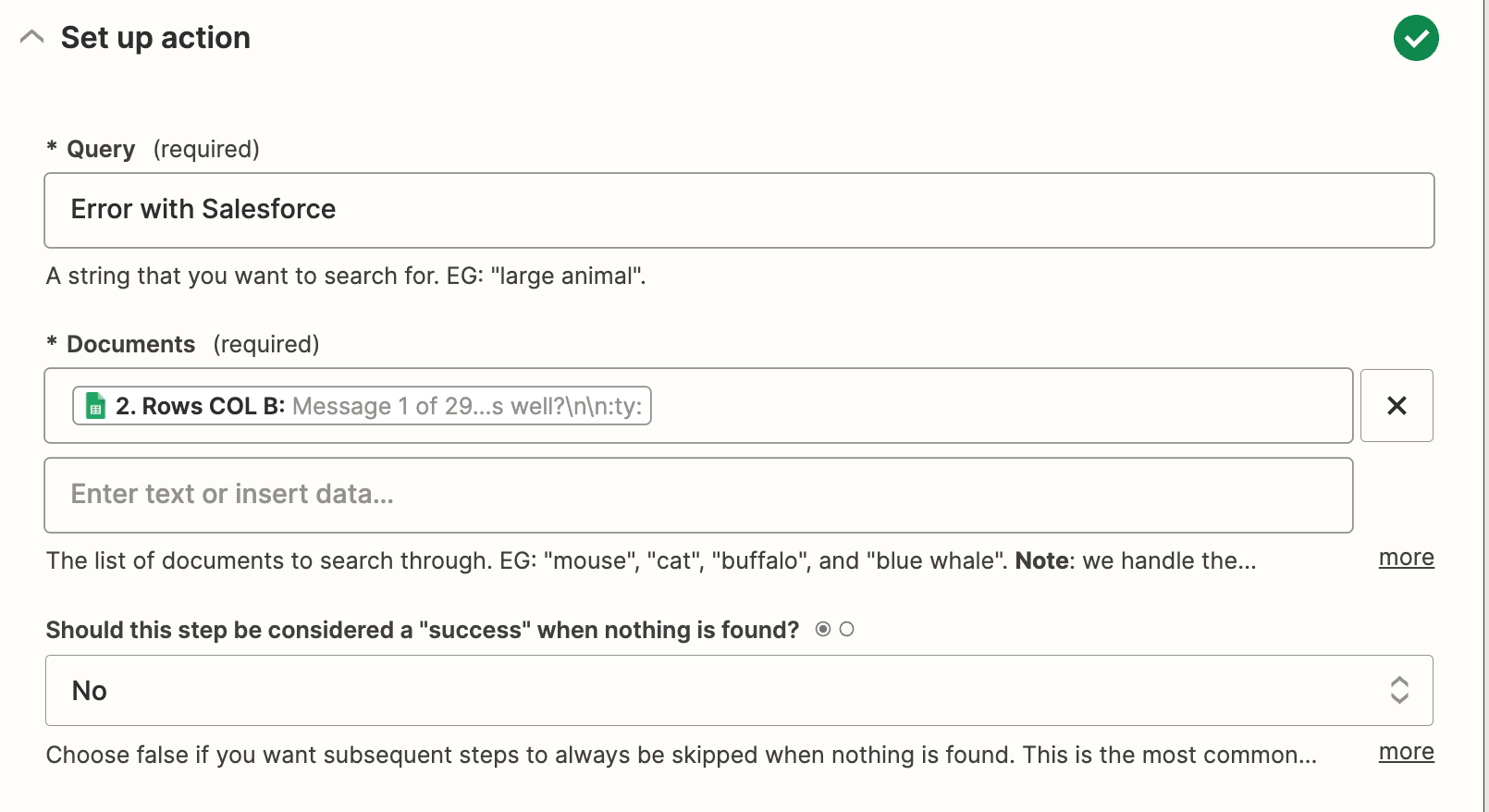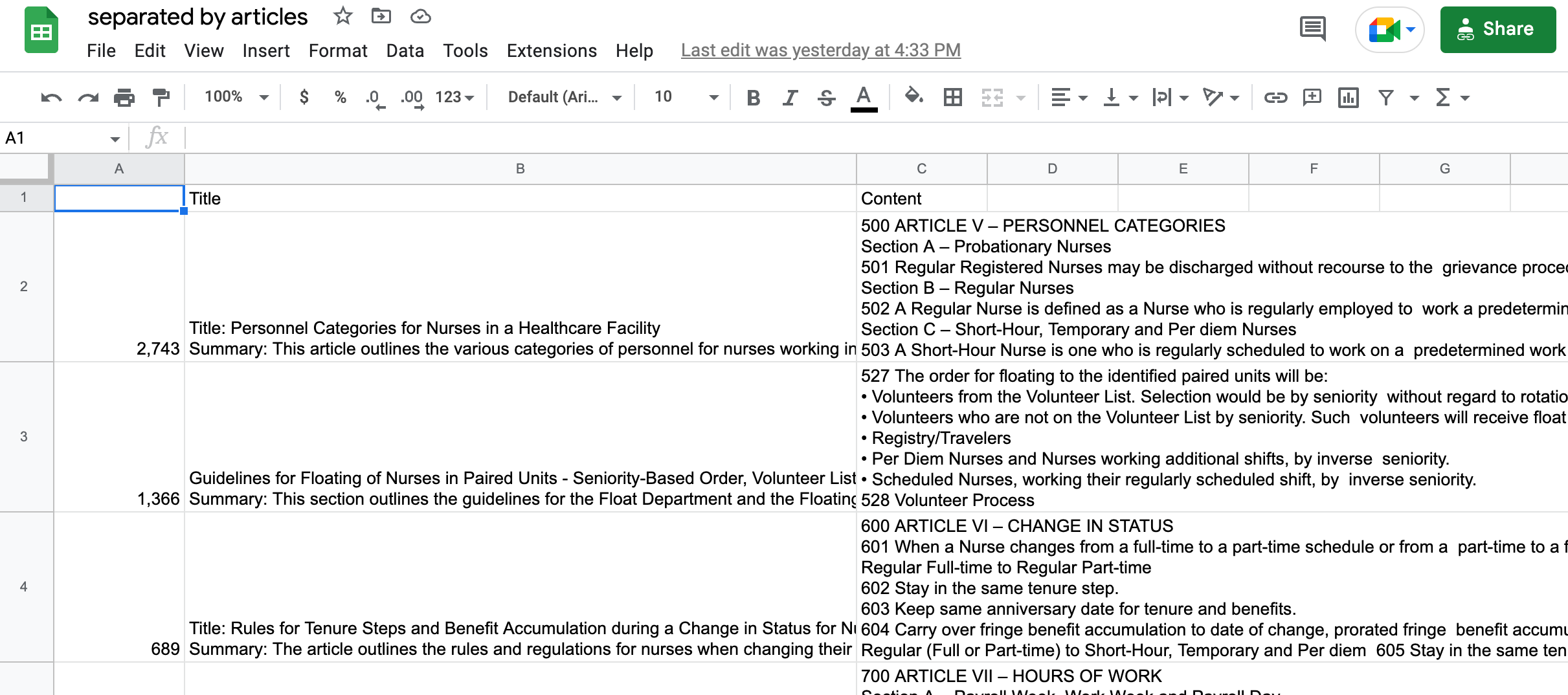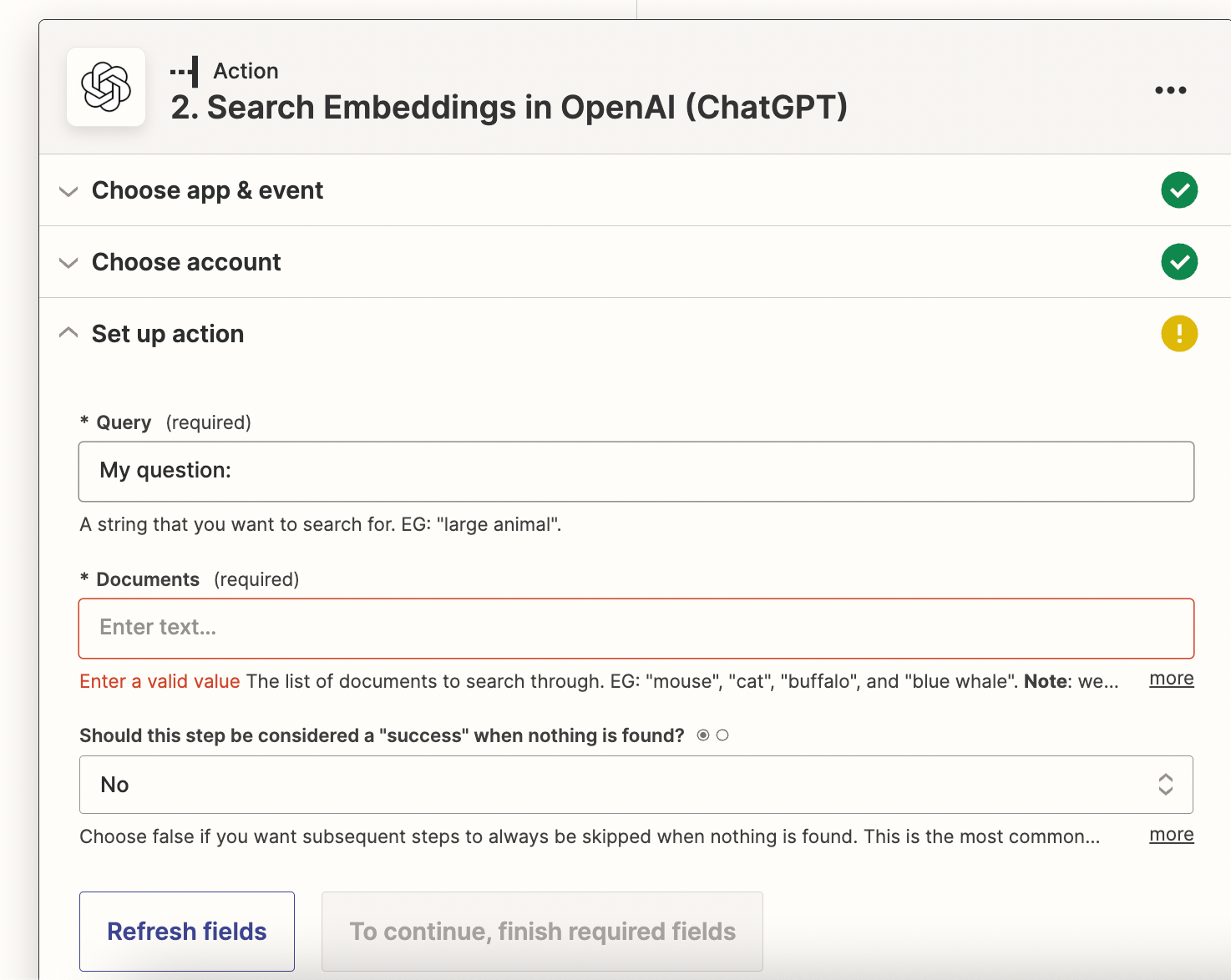
The usual workflow for embeddings is to bulk embed a bunch of documents and then use those documents to compare against the question.
I don’t understand what the “Documents” stand for here. It seems I should just have the original strings to search against? Or is it my embeddings file that I can insert here. In that case - how do I link it here?