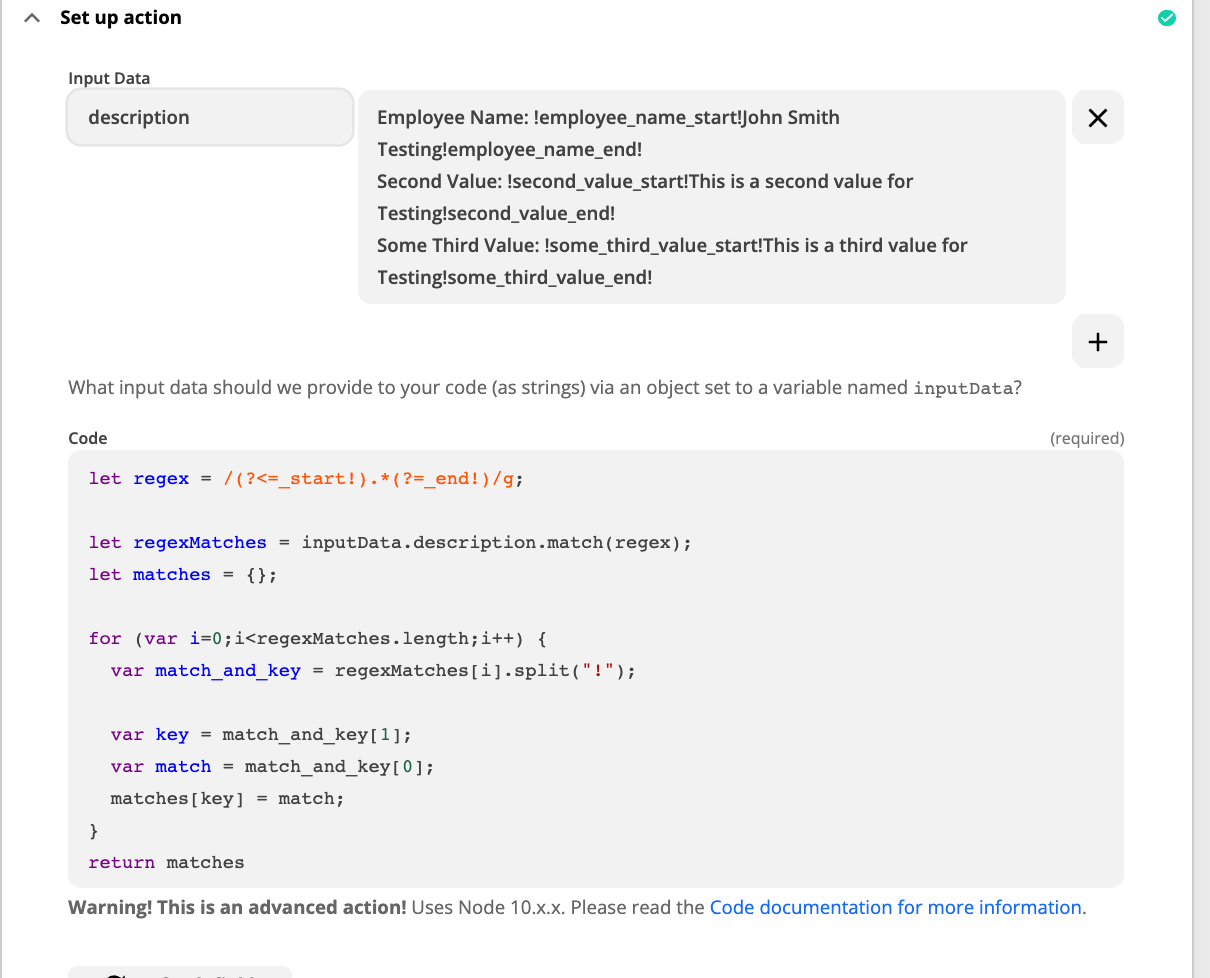
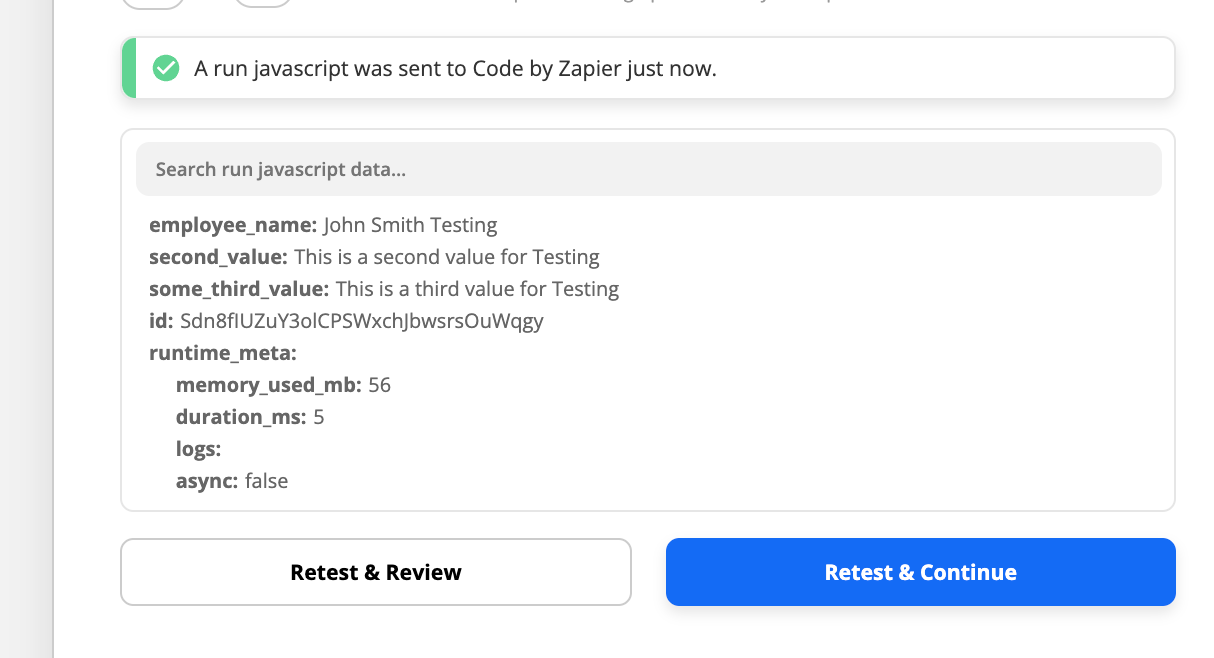
The end goal is to use a start and end tag to put around content dynamically entered by a user in a form and extract that to a field in Zendesk.
The data coming into Zendesk will look like this:
Employee Name: !employee_name_start!John Smith Testing!employee_name_end!
The tags are hidden via html 0 size font but are around the dynamically entered content from the user (John Smith Testing). I want to look for the start tag and grab all data between it and the end tag. I have also tried the code below:
import re
m = re.search('!employee_name_start!(.+?)!employee_name_end!', Description) if m: found = m.group(1)
My goal is that it will go through the description field (as shown in pic) and look for a starting tag of !employee_name_start! And an ending tag of !employee_name_end! And return whatever is in the middle (.+?) which would be the employees name in this case. My actual description field contains this in it: