
")

I need to be able to automatically visit a url (a blog/news article) and grab the article on that page. These are usually news articles in foreign languages, mainly Arabic.
Zapier Web Parser
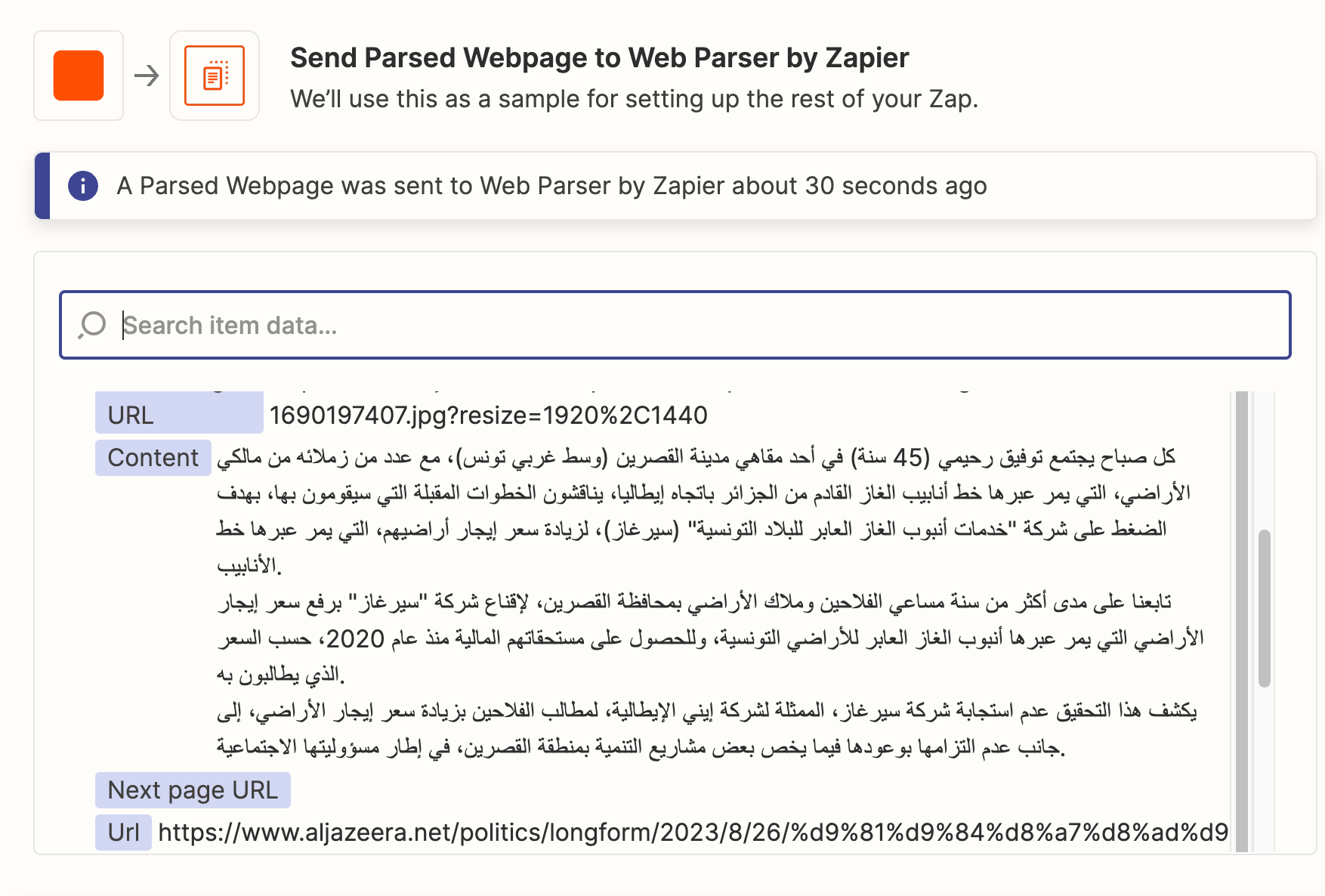
I've had a look at several tools that scrape web data including Zapier’s web parser. Unfortunately, it doesn’t work when I pass it some article pages, such as this one from Aljazeera News. The parser returns only a small part of the article. See screenshot below.
Apify
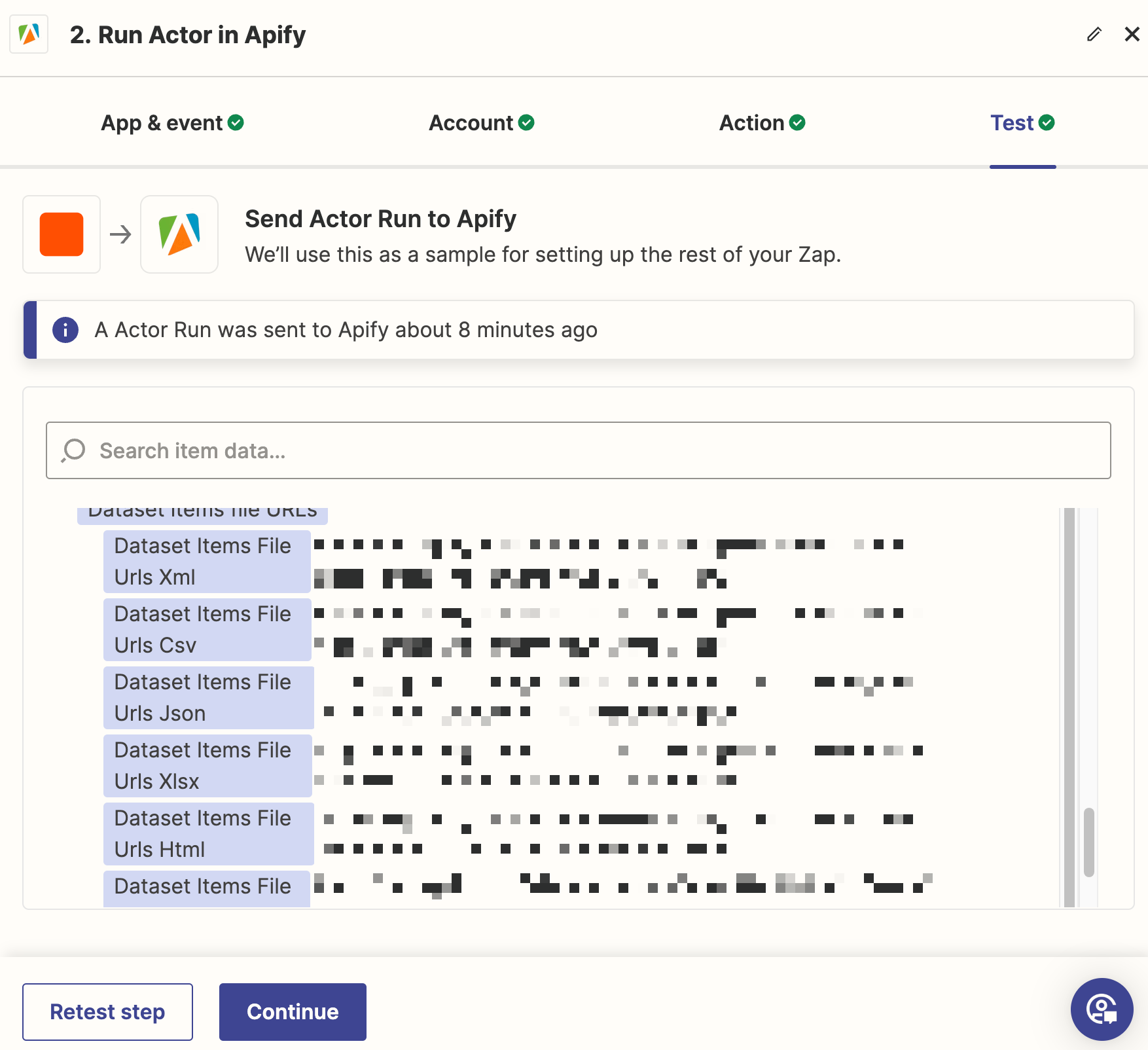
So I tried using Apify's web scraper and it does indeed extract the web content. It returns some links including the below ‘dataset items file urls CSV’, which I then pass to a Files by Zapier step to extract the content as line items. One of those line items is the text content of the article.
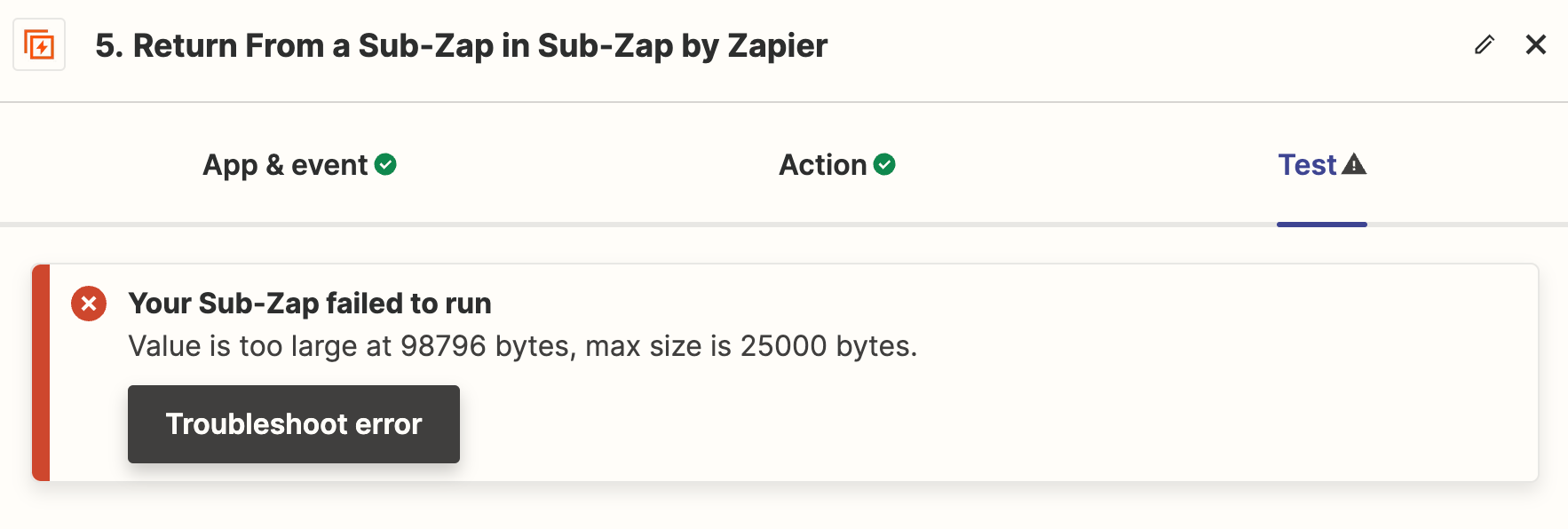
However, my problem is now that this action is within a sub-zap, and I need to return the extracted content back to my main zap. And this fails due to the value being too large. See screenshot:
I feel like I’m almost there, but have a hit a wall.
Do you have any advice on solving the above error? I don’t know why it’s ‘too large’ because it’s just the raw text content of the article, and I can’t see how text content can be that memory intensive.


