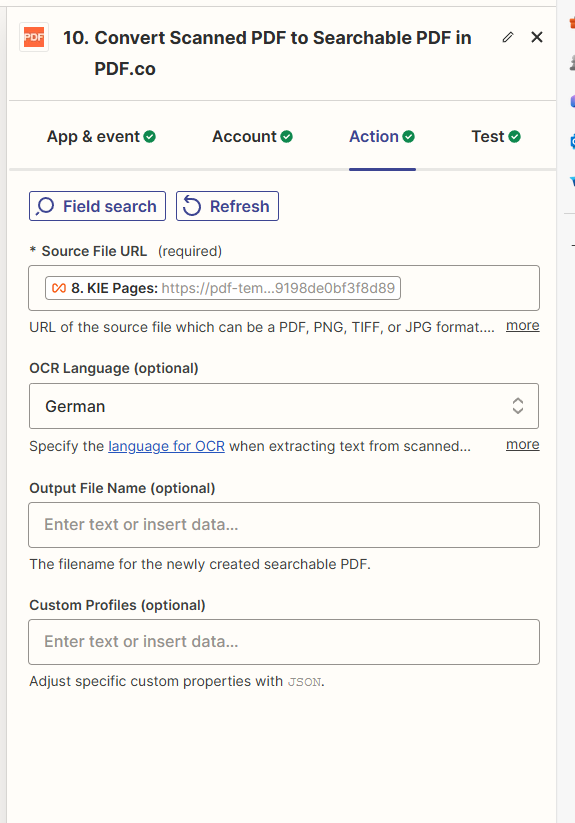
Hi there,
I have an issue with looping step when converting a scanned pdf to a searchable one using pdf.co.
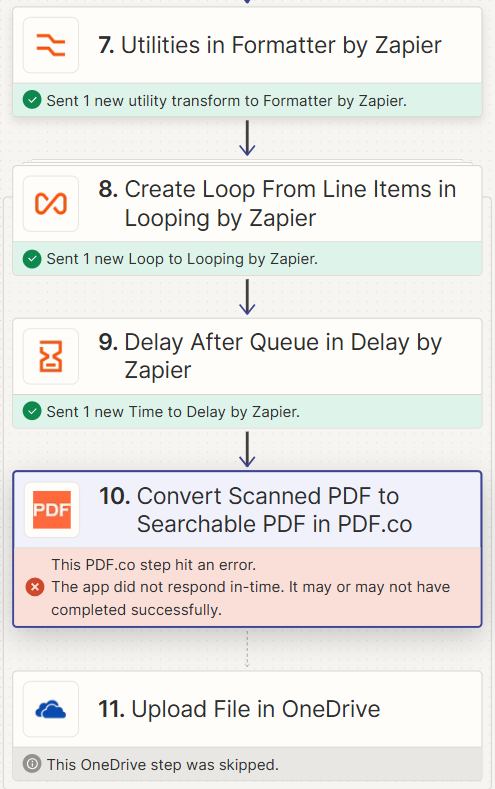
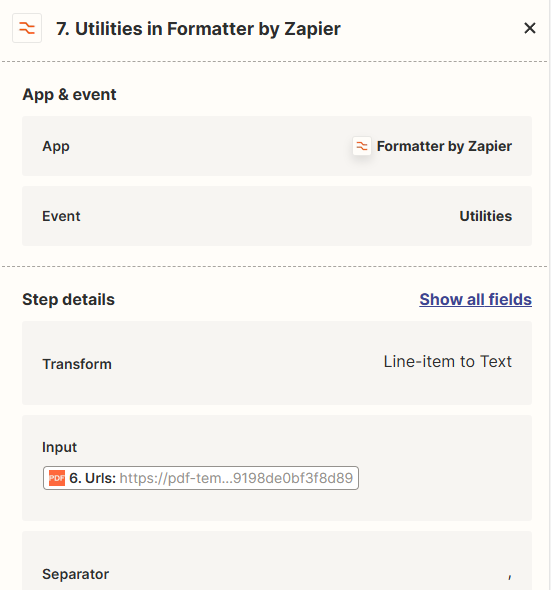
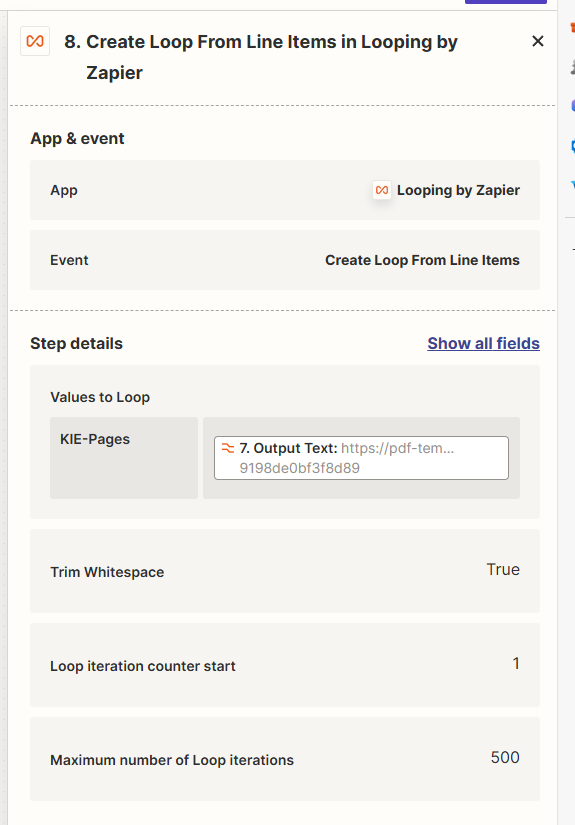
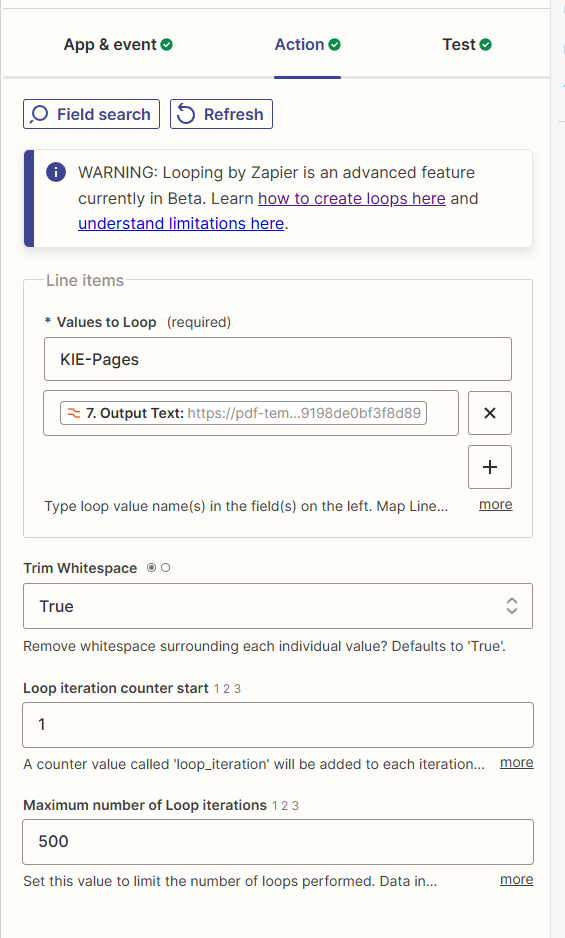
I have a list of different URLs for scanned PDF that are processed with the loop app, as I thought that step 8-11 will be running separately for each URL.
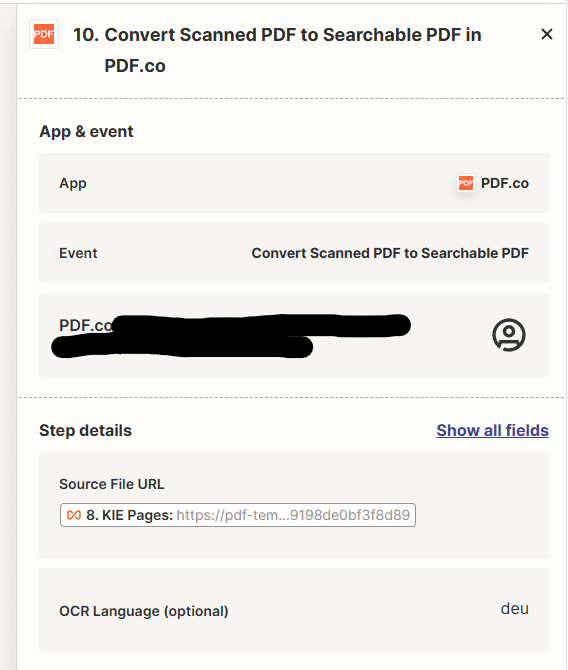
However, checking the log in step 10, the URLs seem to be submitted together to pdf.co (the pdf is public, so no problem that the url is visible here):
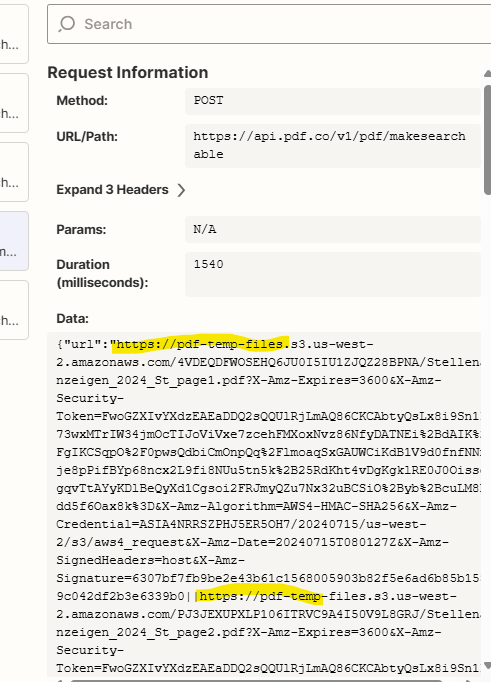
As a result, the step is timing out and the zap does not finish. I think it is because he tries to work on all URL’s at the same time.
I do have a problem now finding the solution because I need to understand if the problem is within the loop or not…
Hoping for some help here :-) Thanks