
Hi guys!
I'm trying to make a Zap to transfer text from a Google Doc into OpenAI for subsequent summary preparation. The challenge is that large texts cannot be directly transferred to OpenAI due to a token limit of 4097. Thus, I plan to divide the large text into smaller segments, send each to OpenAI, and then synthesize the results into a single output.
This pipeline is well-described in this video (https://youtu.be/mdqr85ZtKYs?t=556). I used it as a guide when creating my Zap, which functions perfectly on the reference model.
The process follows these steps:
- Identify a new document in a Google Doc folder.
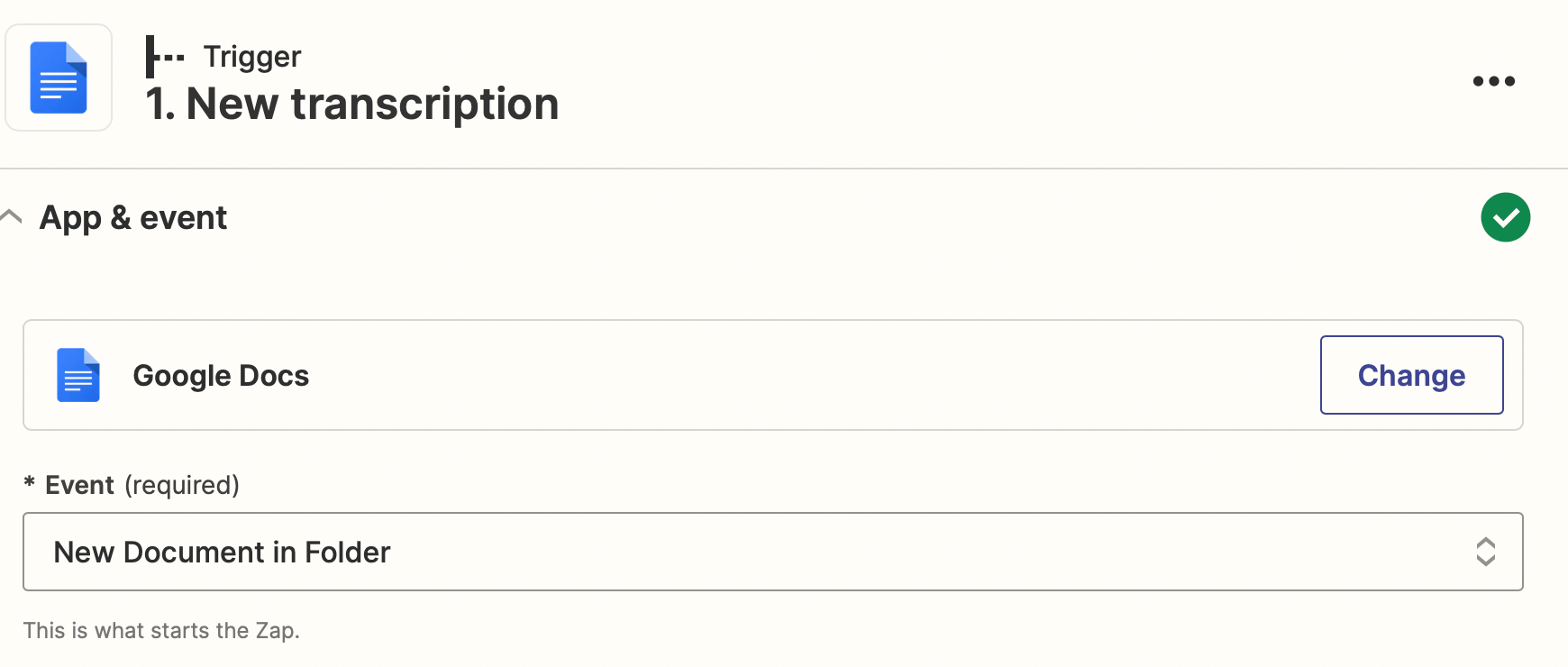
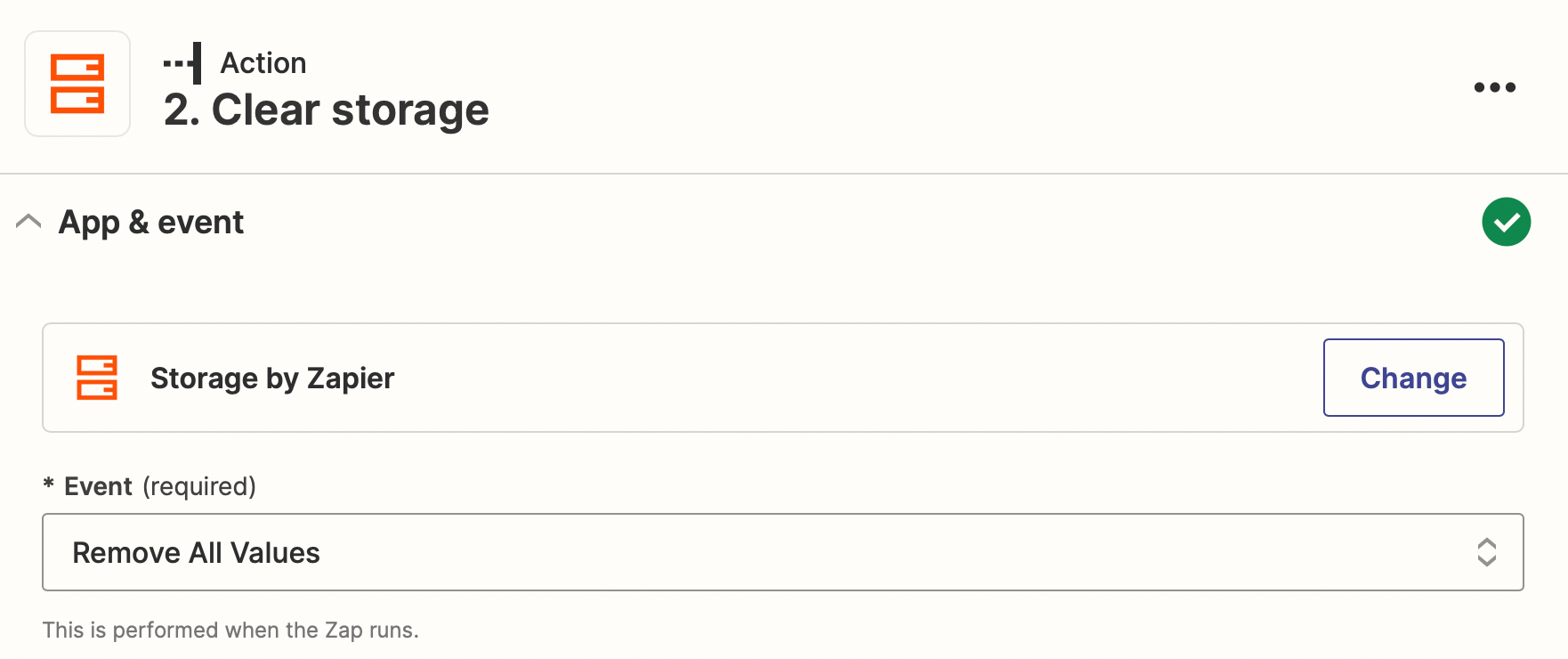
- Clear temporary storage with Zapier Storage at each Zap launch.
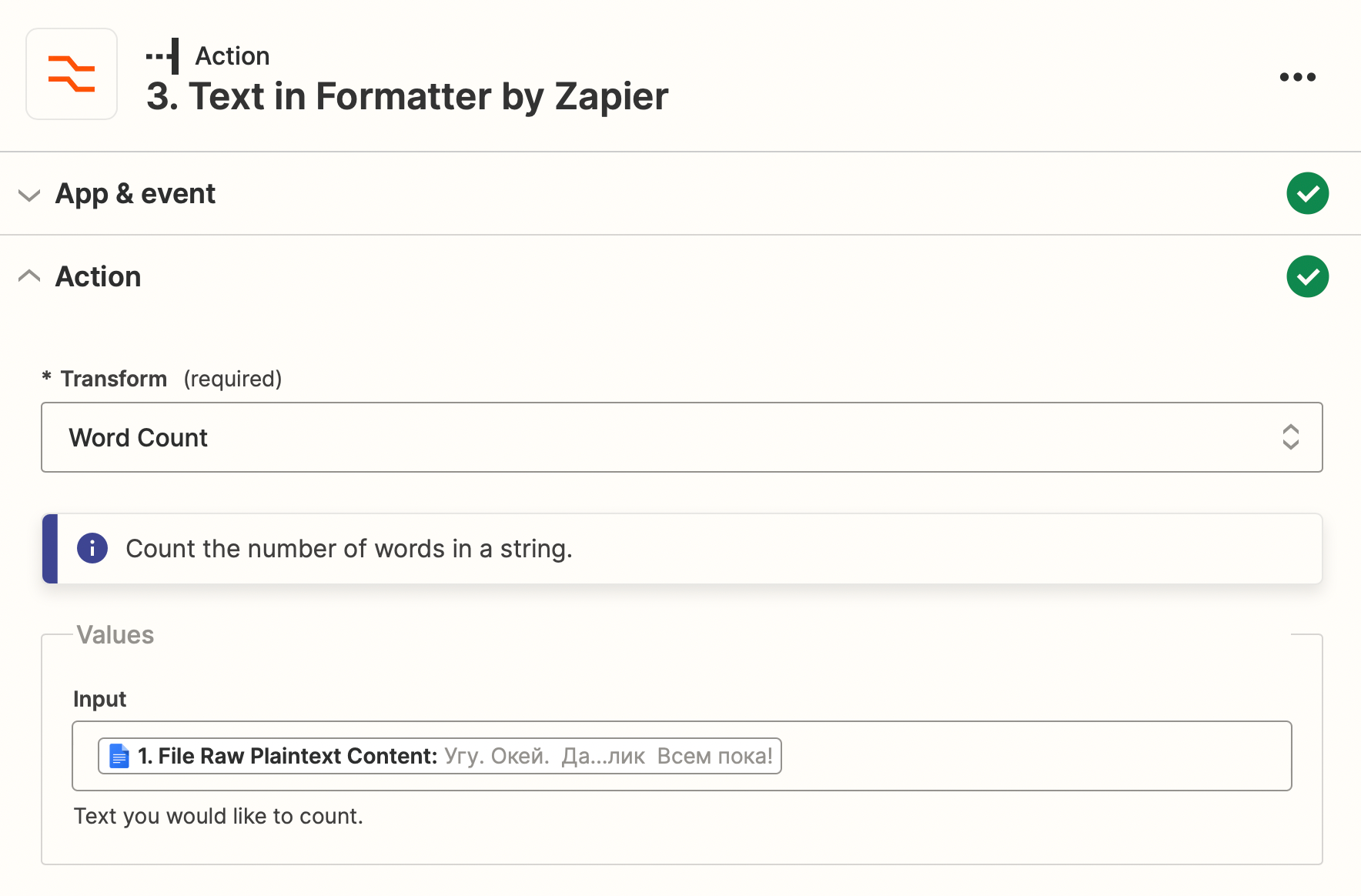
- Determine the number of words in the source document with Zapier Formatter. In my case, the document contains 7518 Cyrillic words.
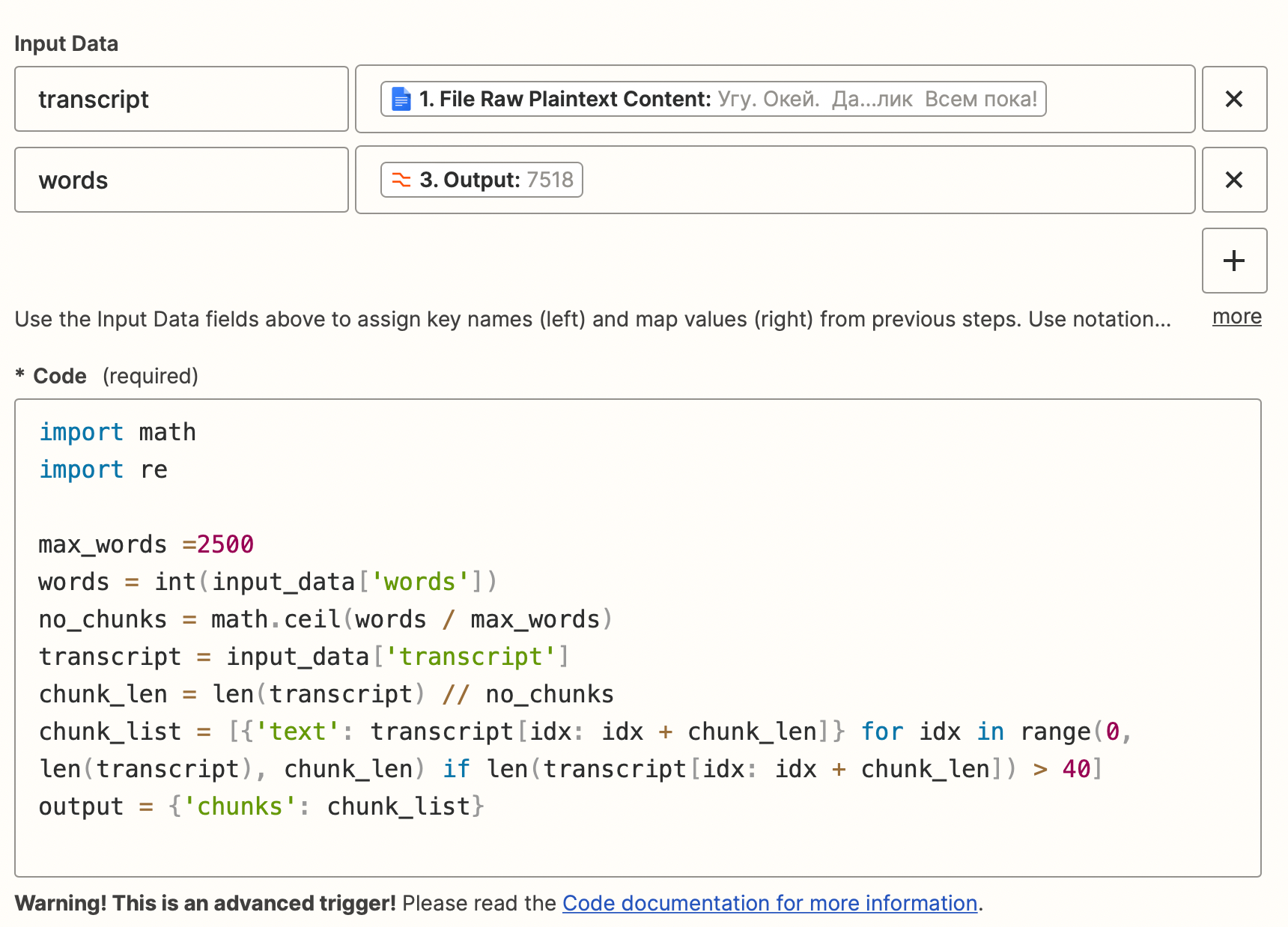
- Cut the large text into pieces of 2500 words with Zapier Code.
- Loop the subsequent algorithm for all segments with Zapier Looping.
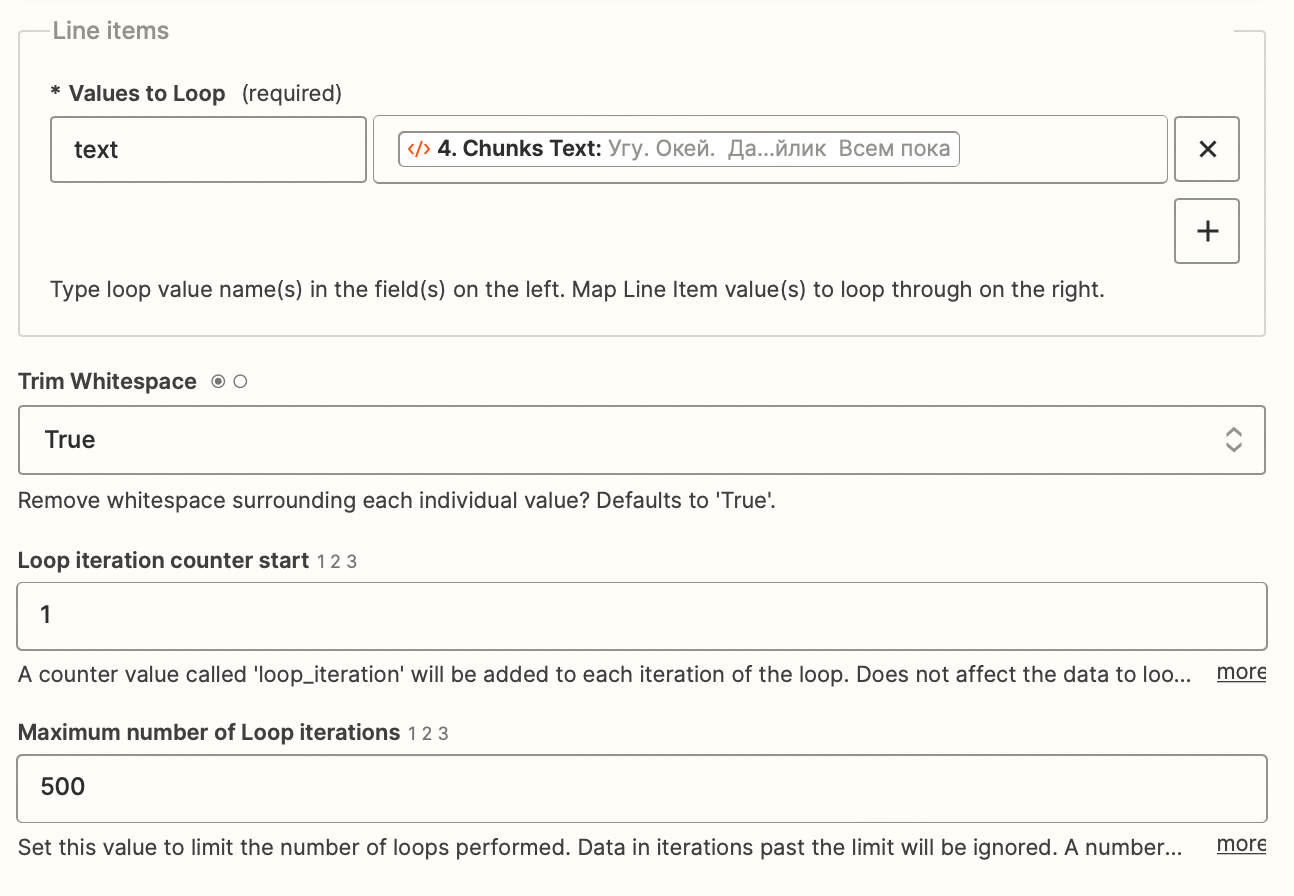
- Send the prompt to OpenAI.
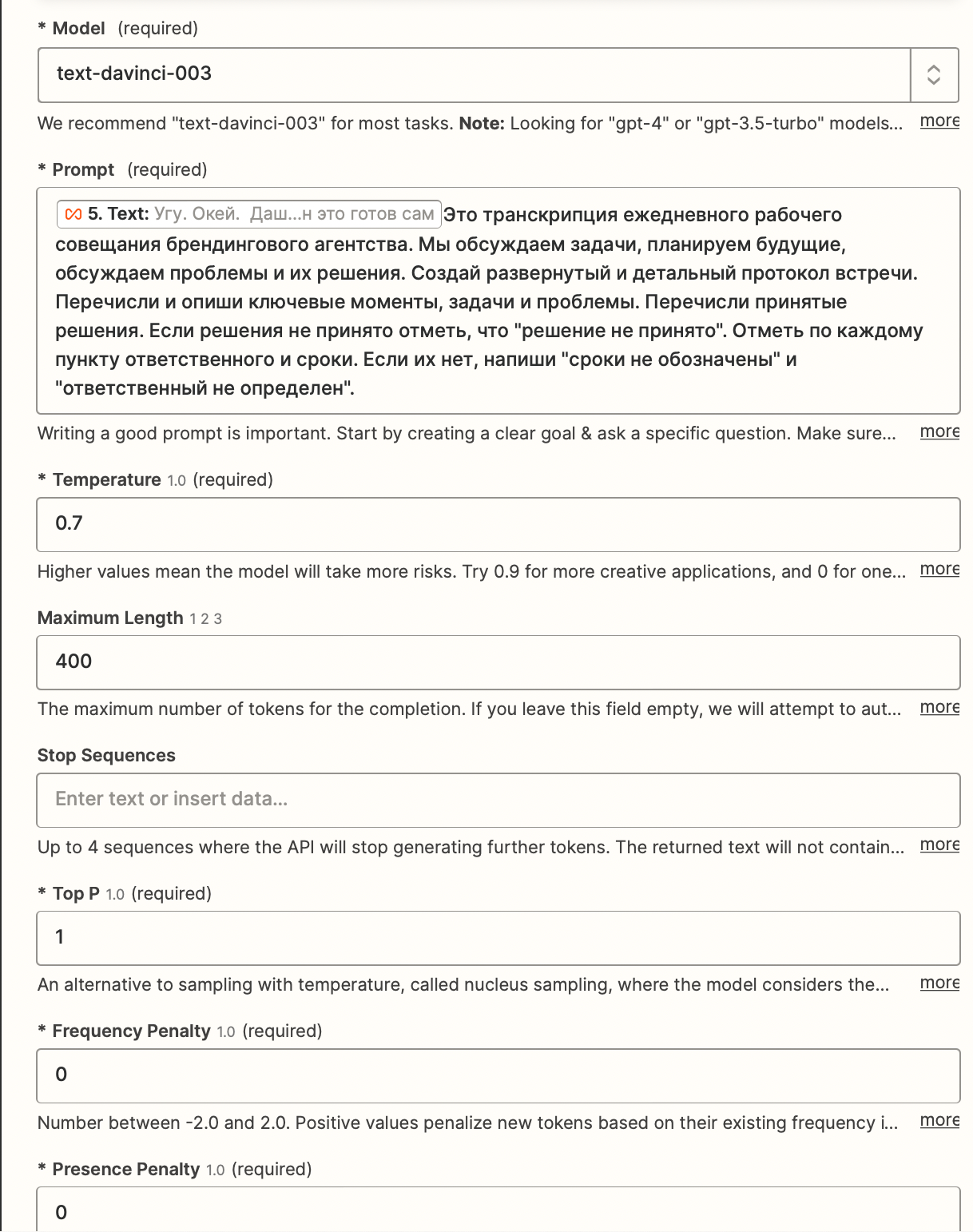
However, I'm encountering an issue.
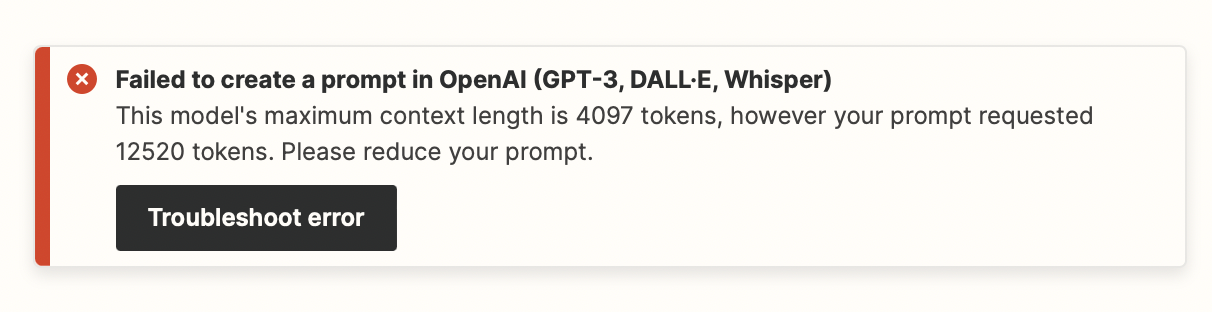
If I use a Cyrillic text, Zapier reports an error, indicating that I requested more tokens than the model's maximum context length of 4097. Adjusting the number of words in each text segment doesn't affect the total tokens requested. Even altering the volume of the source document (though it deviates from the task conditions) hasn't resolved the issue.
Interestingly, when I use an English text as input, there are no issues, and the action works fine.
I can't figure out where to look for the error or what I should do to get past this step with a Cyrillic document.
Any help or tip would be much appreciated.



