Hi Community!
I wasn’t able to get a clear solution from the support team on this so wanted to see if anyone on the Community had any suggestions.
We are pulling information from automated emails produced by a CRM system we use in to a Google Sheet using the Email Parser and a Zap.
The automated emails have a number of templates, and generally are working well, with fields being correctly found, and data is appearing 80% of the time in the correct cells and columns in the sheet.
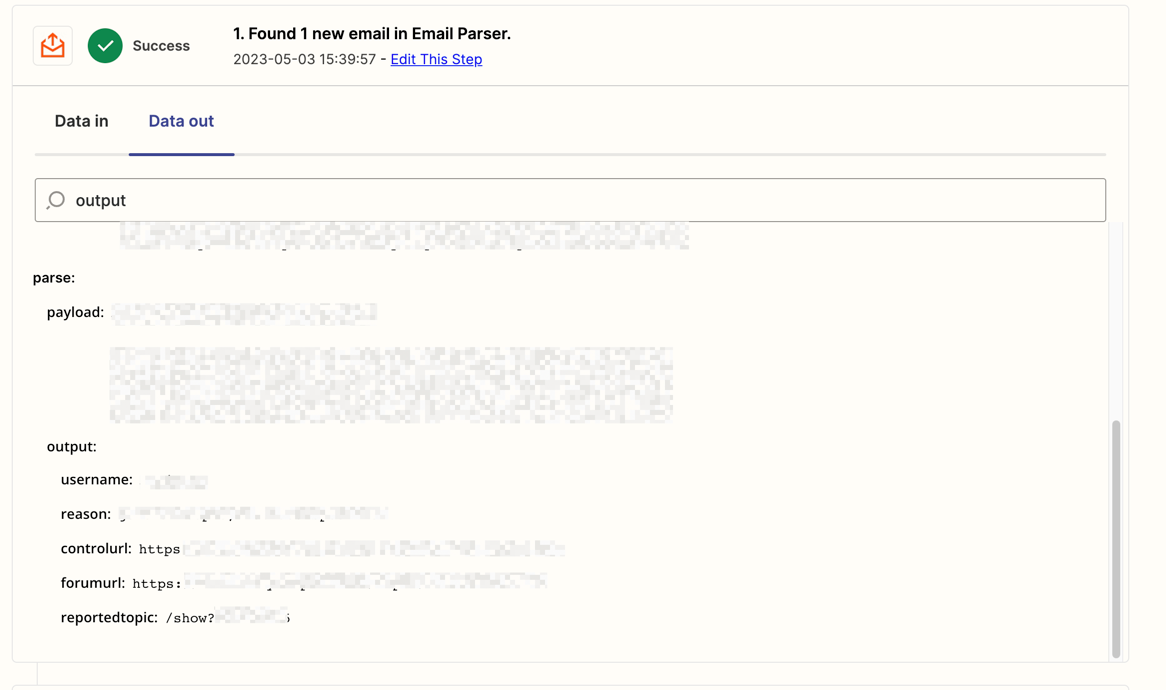
However, issues arise when some of the fields set up in the Zap for each cell are not in the emails. The parser data for the email is correct when you look at the ‘output’, but because the Zap expects this field data when it runs, instead of leaving the cell empty, it starts pulling data from another random bit of the email.
I’d like to have a rule that says if field A exists in a Zap, but field B does not, just ignore it.
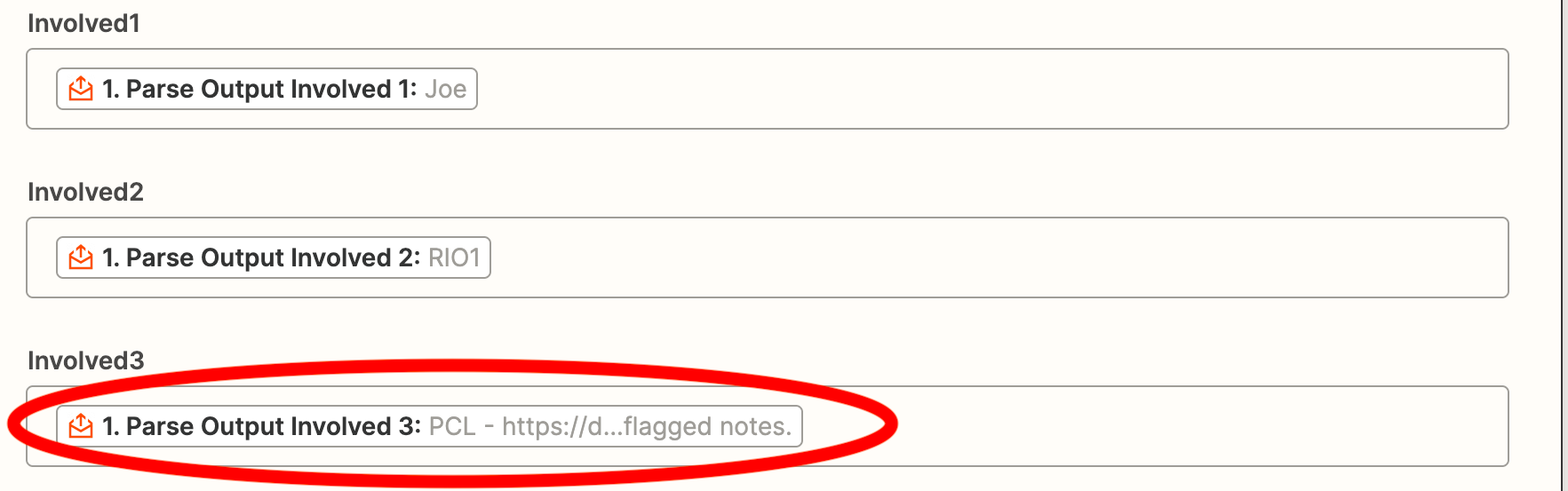
Here is a snapshot of two different email sections, one contains 3 fields we want, the second just 2. If the Zap itself does not get the 3rd involved field, it often pulls random sections of email and puts it in the cell with the first two.
In the first email example below you can see that there are three fields marked as 'Involved':
--> Staff: *{{involved1}}*
--> Equipment/Machines: *{{involved2}}*
--> Suites/Workstations: *Suite 1*: *{{involved3}}*
In this example, there are only 2 from the automated email, there is no third stated:
--> Staff: *{{involved1}}*
--> Equipment/Machines: *{{involved2}}*
Any suggestions on how to have the Zap ignore the fact that there is not a involved3 in the ‘output’ and not try and fill the cell with random information?
Thank you!
Thomas