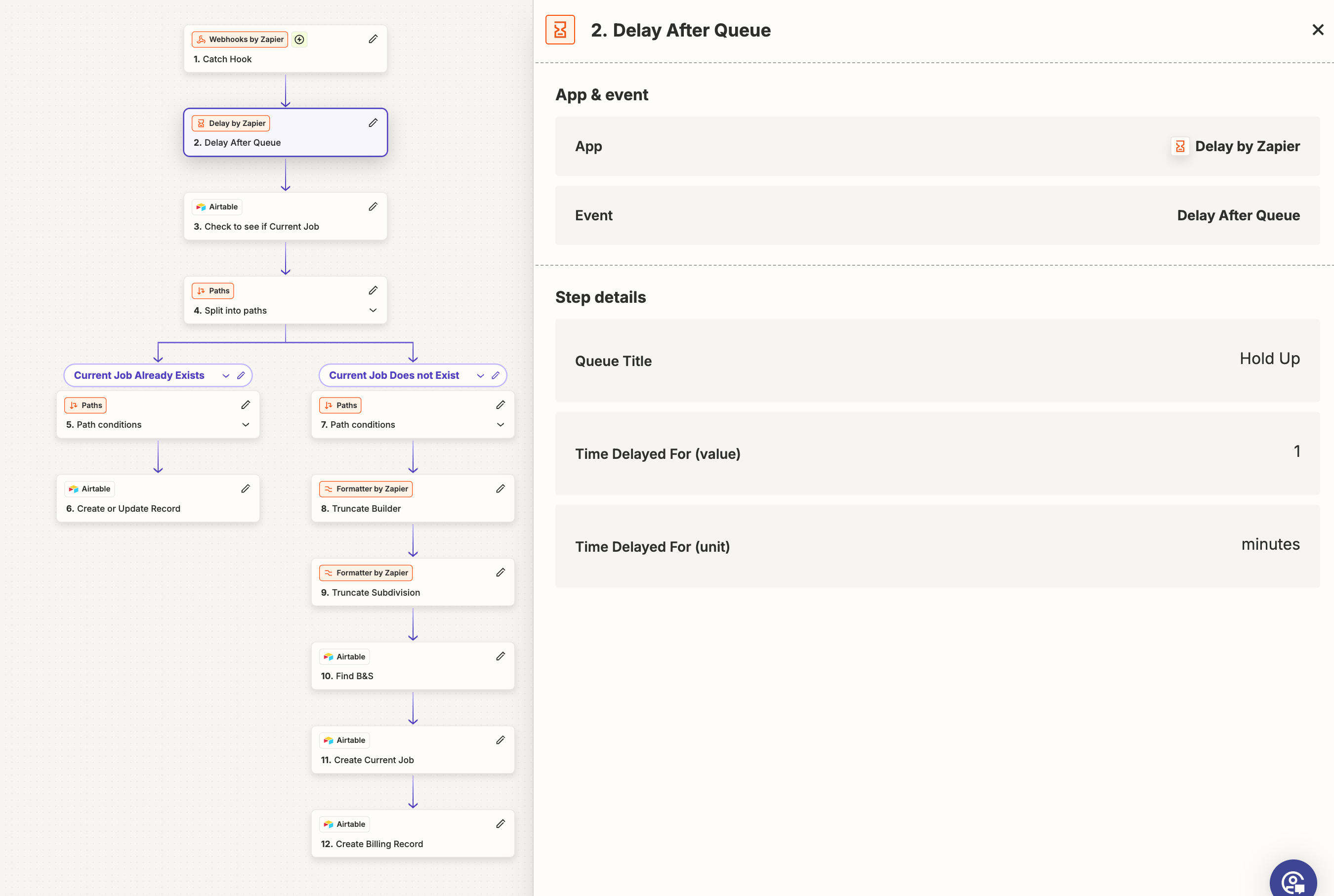
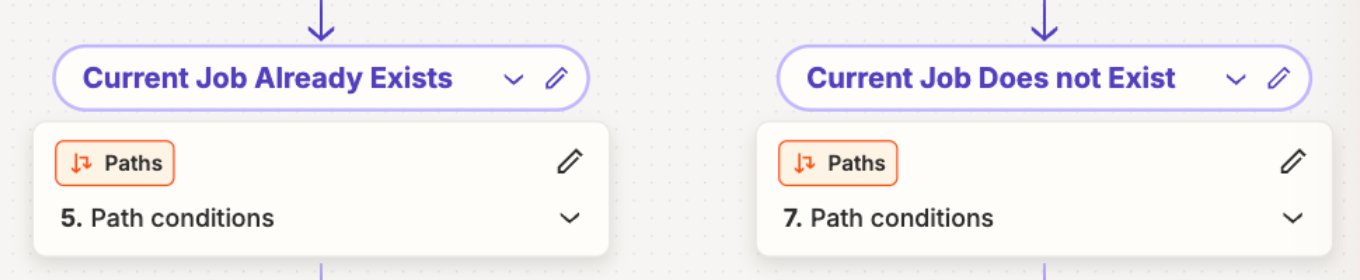
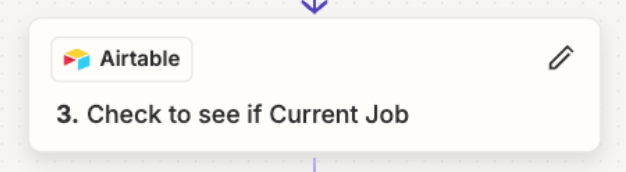
I’m processing POs in Rossum(AI data extraction), which sends the extracted data to a Zap to create a record in Airtable. These POs are for work to be done on houses and each house gets 3 or 4 POs. I have a table for houses(1 record for the house) and a table for POs(1 record for each PO) that are linked to the parent record. The house record doesn’t exist until the first PO comes through. I search to see if the house record exists. If it does then I create the PO record and link it to the house. If the house isn’t in Airtable, I create it and then create the PO record and link it to the house. Sometimes this process will create multiple records for the house(Parent records), which creates a duplicate problem. I’m using the zap step to process them in a queue with a delay so that it gives each one time to run and find everything, but it still will create duplicates sometimes. This makes me think Zapier has an “image” of the table that it uses to search for the house instead of doing a fresh pull of the data every time and its searching old data. I’m just making that up in my head, but somehow its still creating duplicates.
Finally the question: Would using a Zapier table be faster or more reliable for these searches? My AT table is 50k+ records and 300 fields. Is having a light weight database mirror a method to increase speed?
PO data comes in. Zap searches Zap table for address. It doesn’t exist, create AT record and then store the Address and record_ID info in a Zap table for the next PO to search for it there instead of the AT search.