We have been using Printavo to manage our screen print/embroidery shop. We have a couple of large customers for jobs completed within the last two weeks.
I would like to;
Identify jobs for Customer A that are complete
Find the URL to the actual invoice.pdf for that job
Download the file to a OneDrive folder
1 and 2 are not the issue; I’m damned if I can find the easy, straightforward way to accomplish 3. I have the URL, I have the OneDrive connected. I need the rough equivalent of
Yes, that was my conclusion. Surely there is a way to do this, short of rolling the Printavo API into my own shell script (which I would prefer not to do)?
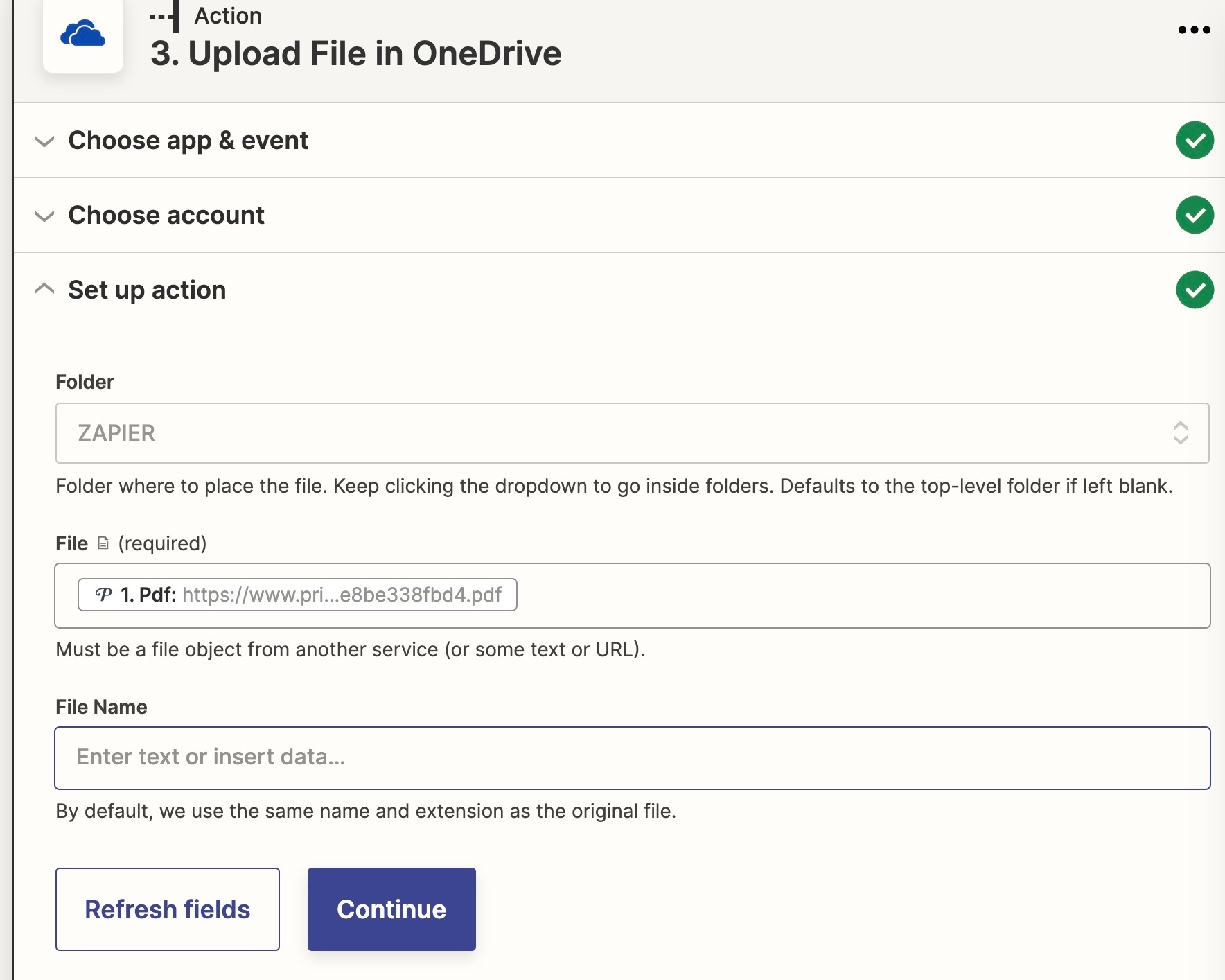
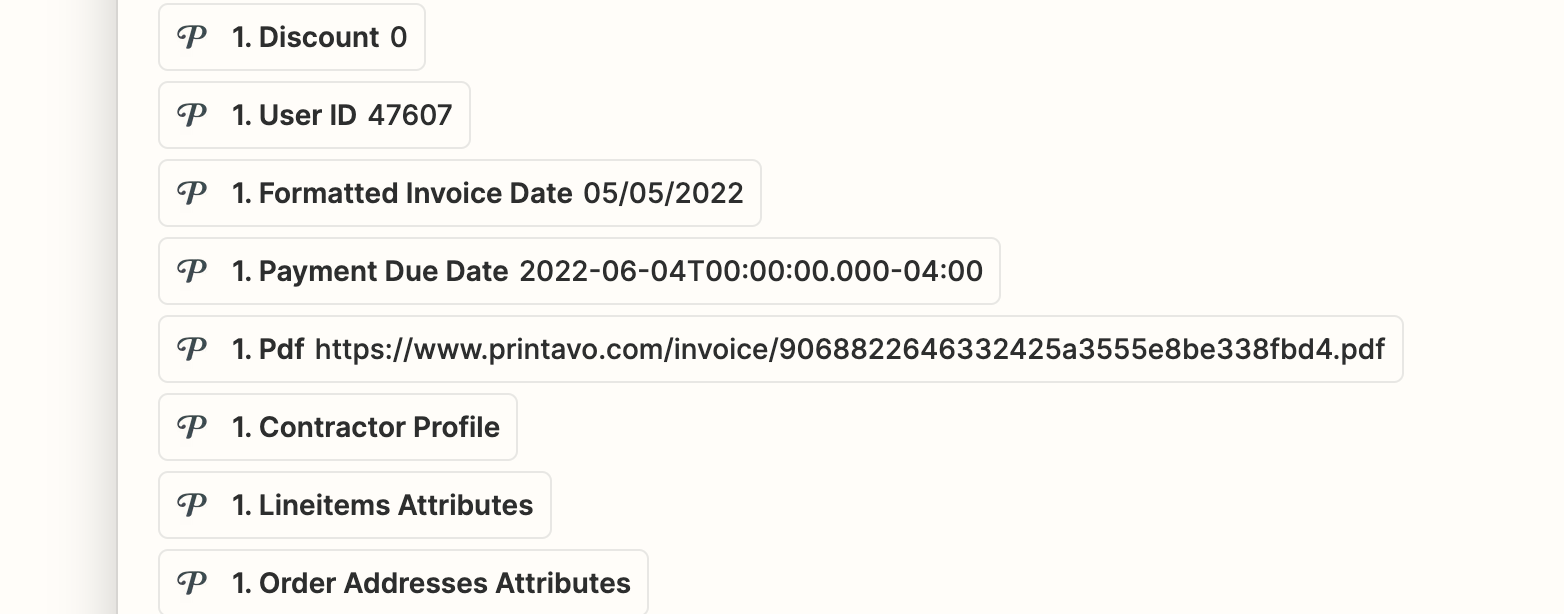
Aha. The Zapier field (Pdf) -- which should contain the download link to the actual file, and appears to in the editor -- is actually giving me the parent page. Verified this by pasting the expected URL instead of using the field value.
Huh. That’s exactly what I’ve been doing. It worked when I pasted the URL. It does not work when I use the variable/PDF field.
I see now that the variable field is incorrect -- it says “www’ where it should say “spectrumdesigns”. The “www.printavo.com” page is nothing more than an HTML redirect to the parent page:
<html><body>You are being <ahref="https://spectrumdesigns.printavo.com/invoice/9068822646332425a3555e8be338fbd4">redirected</a>.</body></html>
Looks like I’ll have to use Javascript or Python to get this done.