I have an api endpoint from which i only have the option to get a list of endusers, no new row or update row capability, but i can sort the list i.e. by last change date, and limit how many records i take out.
My question is how do I make a zapier flow that 1. Updates exciting records in my postgreSQL server and 2. Create new rows, while at the same time using as few paid tasks as possible with this kind of API endpoint?
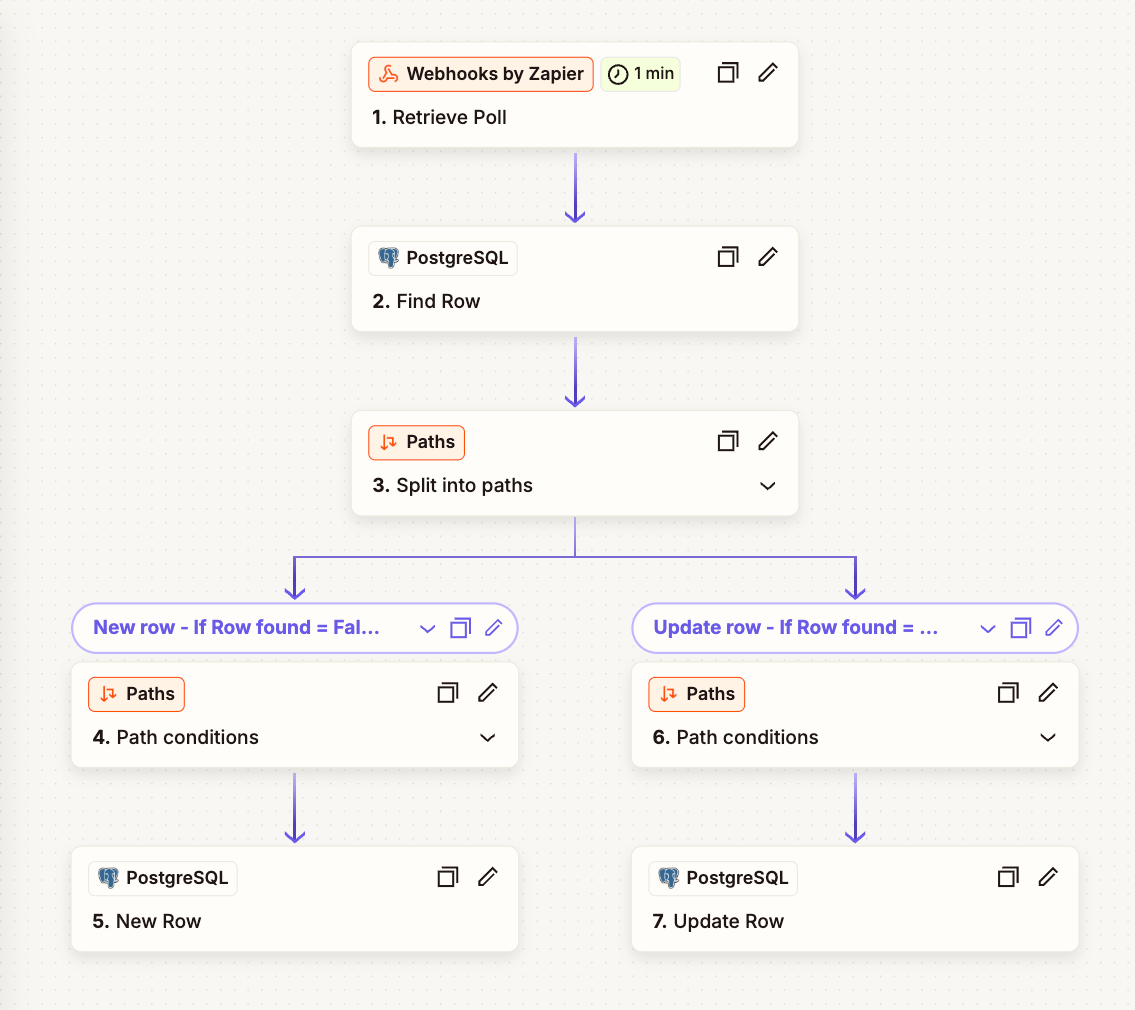
This is my take on it, but very unsure if it’s the best way, or if it even works proper - what do you think?
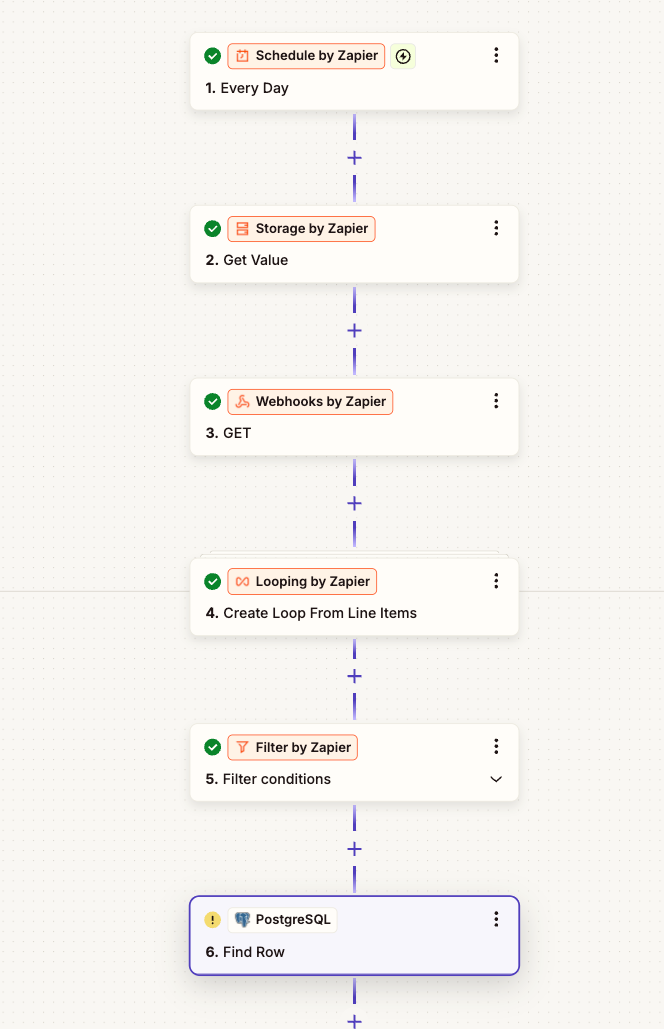
- I run an update each hour
- I get the time + date the zap last ran through storage
- I get a list of endusers from my API endpoint and use (sort=-updatedAt&limit=100) to sort the list by last updated, and limit it to 100 records.
- I use a loop to create max 100 individual records from the JSON list just retrieved
- I use a filter condition to only allow records with a ‘UpdatedAt’ date that is newer than the ‘Zapier storage date’ - last time it ran.
- I take the ID from one record, and search my PostgreSQL database to see if it exists or not
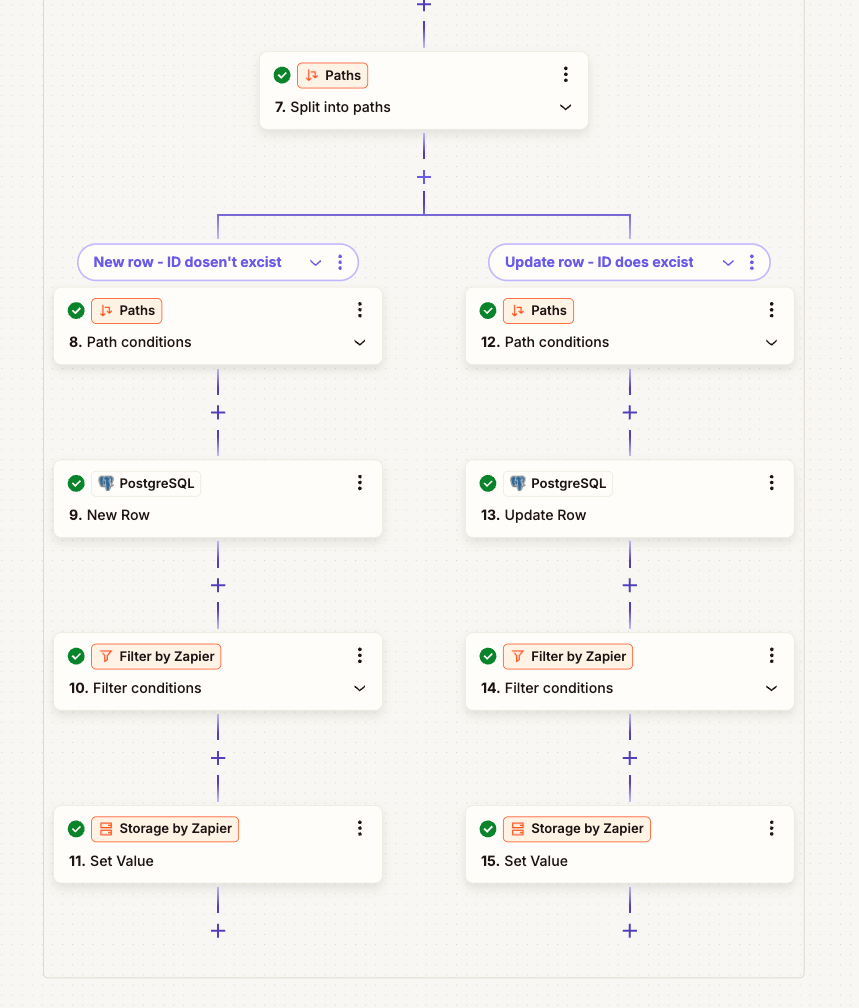
- Split pathway
8/9. If it Dosen’t exists - then I create a new row in PostgreSQL
12/13 If it already exists - then I update the row in PostgreSQL
10/14 - If last loop is true - break loop
11/15 - Set time of zap run i zapier storage