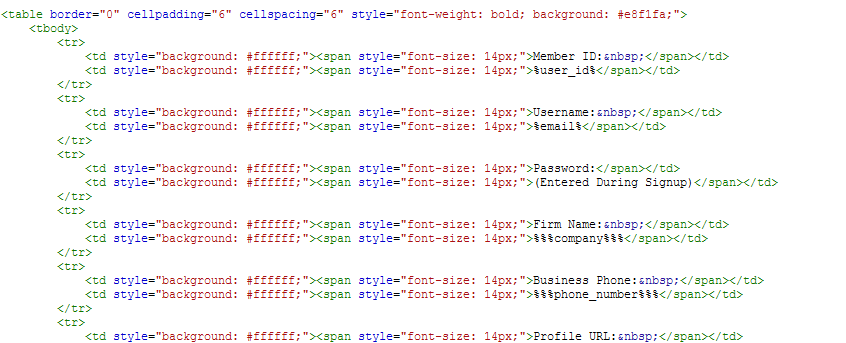
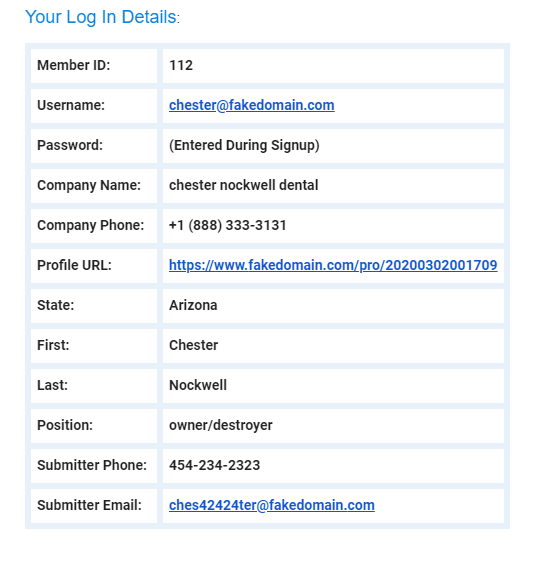
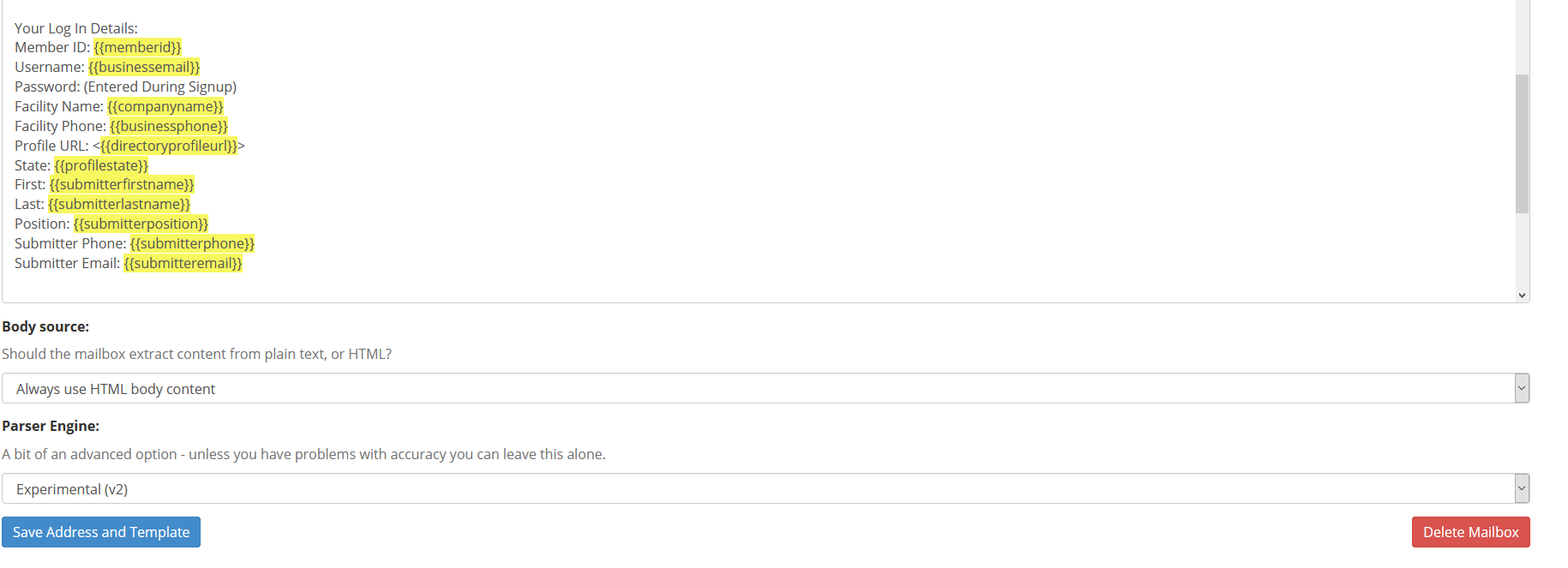
I have complete control over an email that I am trying to parse but I can not get the fields to strip out correctly consistently. I’ve tried all 3 combinations of the parser engine as well as the text and html layouts. I have all of the data in an HTML table in the format that I’ve attached as an image.
Everything is on different lines and I’ve used : to separate out the title from the variable and included the space html after. It gets it most of the time and I’ve trained so so so so so many extra templates with data entry variations but yet it still messes up. I tried reaching out to Zapier support to get some sort of indication of what the parser looks for but I got nothing. It seems that if I could put in <div id=”variable1”> tags or something to wrap my exact variables, I should be able to get this very easily. I just don’t know what to wrap them in or how to design / code my email.
Can anyone help me out? I’ve spent more hours than I can count on this and when I finally think I’ve gotten it, it breaks and having it break causes a huge problem for a part of my business. Thanks!