


Hi Zapier Community,
I'm working on a Zap designed to automatically process a CSV file received daily as an email attachment and use it to update or create records in a Zapier Table. I've gotten close, but I'm running into some confusing issues, particularly with testing steps inside a loop.
My Goal:
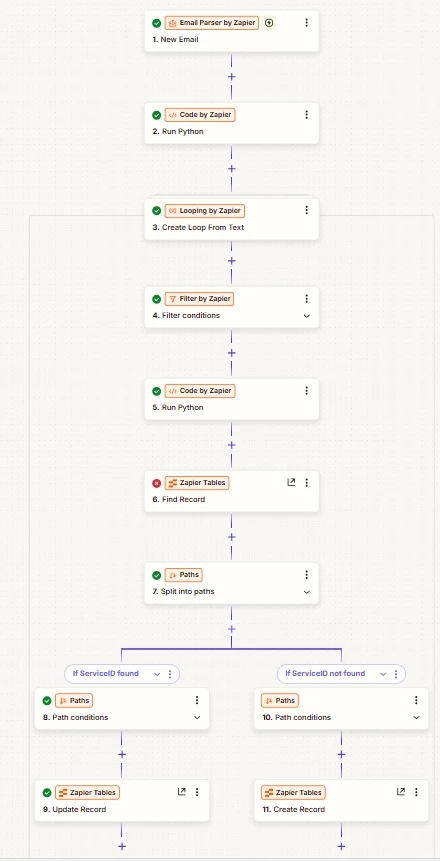
Receive daily email -> Parse CSV attachment -> For each row: Find record in Zapier Tables by entityInterface, if found Update, if not found Create.
My Current Workflow:
-
Trigger: Email Parser by Zapier (New Email - gets attachment)
-
Action: Code by Zapier (Run Python) - Fetches the attachment content via URL and returns the entire CSV content as a single text string (e.g., in an output field named csv_content). (Reason: Tried outputting a list/line items directly, but hit the 250 item limit).
-
Action: Looping by Zapier - Create Loop From Text
-
Input Text: Mapped to csv_content from Step 2.
-
Text Delimiter: Set to \n (newline).
-
-
Action (Inside Loop): Code by Zapier (Run Python)
-
Input full_text: Mapped to csv_content from Step 2.
-
Input line_number: Mapped to Loop Iteration from Step 3.
-
Code: Parses the specific line (lines[line_number - 1]) from full_text using csv.reader and outputs a dictionary with keys like entityName, entityInterface, Description, OperationalStatus.
-
-
Action (Inside Loop): Zapier Tables (Find Record)
-
Table: My Target Table
-
Lookup Field: Field 2 (This column holds my unique entityInterface values)
-
Lookup Value: Mapped to 4. Run Python -> entityInterface.
-
-
Action (Inside Loop): Paths
-
Path A (Found): Rule checks if 5. Find Record -> Zap Search Was Found Status is true.
-
Path B (Not Found): Rule checks if 5. Find Record -> Zap Search Was Found Status is false.
-
-
Action (Inside Path A): Zapier Tables (Update Record)
-
Record ID: Mapped to 5. Find Record -> Record ID.
-
Field 1 (entityName): Mapped to 4. Run Python -> entityName.
-
Field 3 (Description): Mapped to 4. Run Python -> Description.
-
(Field 2 / entityInterface is NOT mapped here)
-
-
Action (Inside Path B): Zapier Tables (Create Record)
-
Field 1 (entityName): Mapped to 4. Run Python -> entityName.
-
Field 2 (entityInterface): Mapped to 4. Run Python -> entityInterface.
-
Field 3 (Description): Mapped to 4. Run Python -> Description.
-
The Problem / Confusion:
When I test the steps inside the loop (Steps 4, 5, 7, 8), Zapier seems to consistently use data from the first iteration (Loop Iteration = 1).
-
This causes the Step 4 (Run Python) test to show it's outputting the header names (entityName, entityInterface, etc.) as the values.
-
This then causes the Step 5 (Find Record) test to fail ("Nothing could be found") because it's searching Field 2 for the literal text entityInterface.
-
This then causes the Step 7 (Update Record) test to fail ("Cannot create ULID...") because it receives an invalid Record ID from the failed Step 5 test.
My Questions:
-
Is the current workflow approach (Code -> Loop From Text -> Code -> Find -> Paths -> Update/Create) a valid and robust way to handle this, given the Code step item limit?
-
Is it normal for the tests of steps inside a loop to consistently use Iteration 1 data, even if prerequisite steps failed their tests based on that data?
-
Are there any obvious flaws or better ways to configure this?
I feel like the logic is almost right, but the testing experience inside the loop is making it hard to be 100% confident. Any insights or suggestions would be greatly appreciated!
Thanks!

