")

Hi,
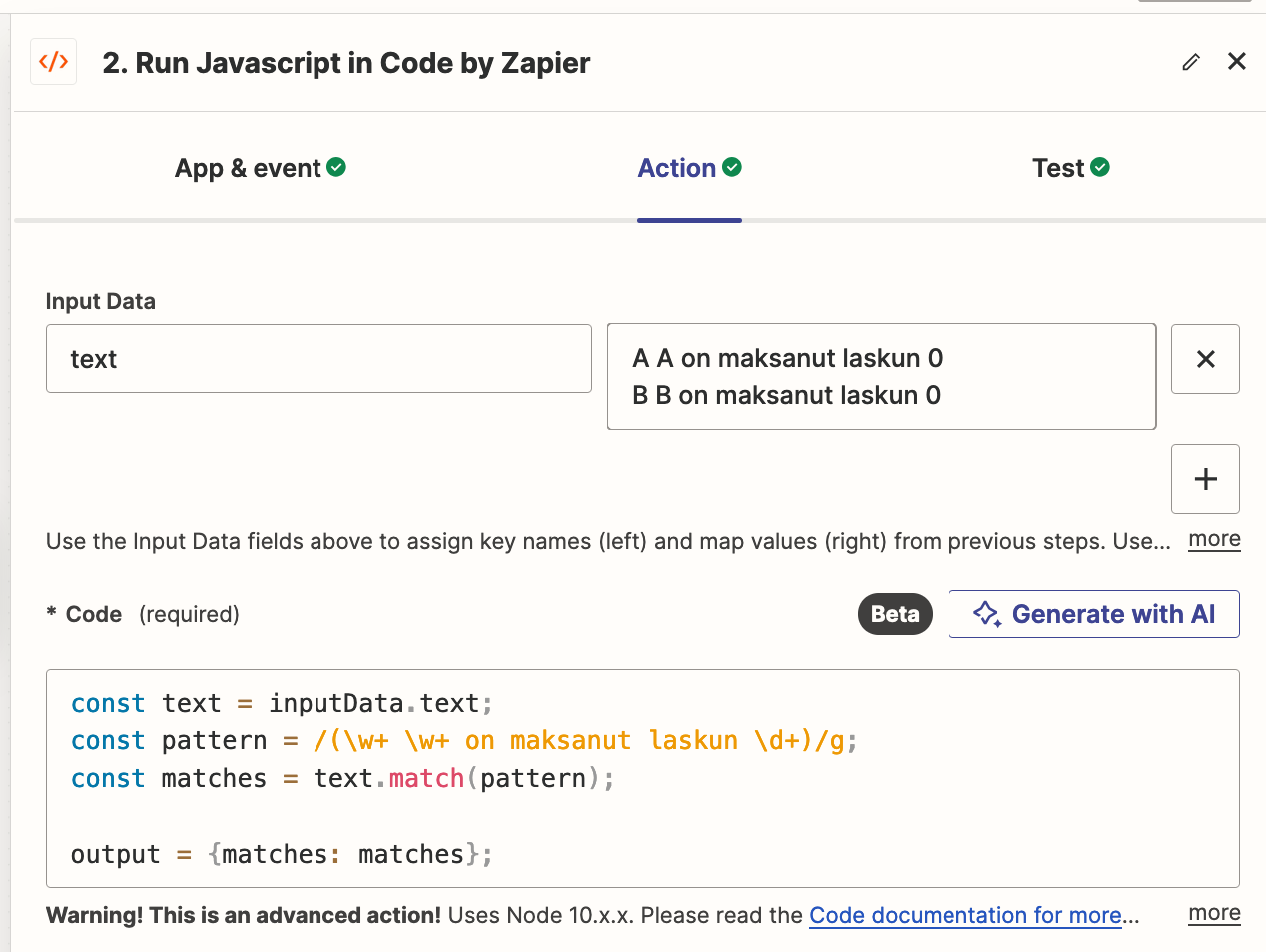
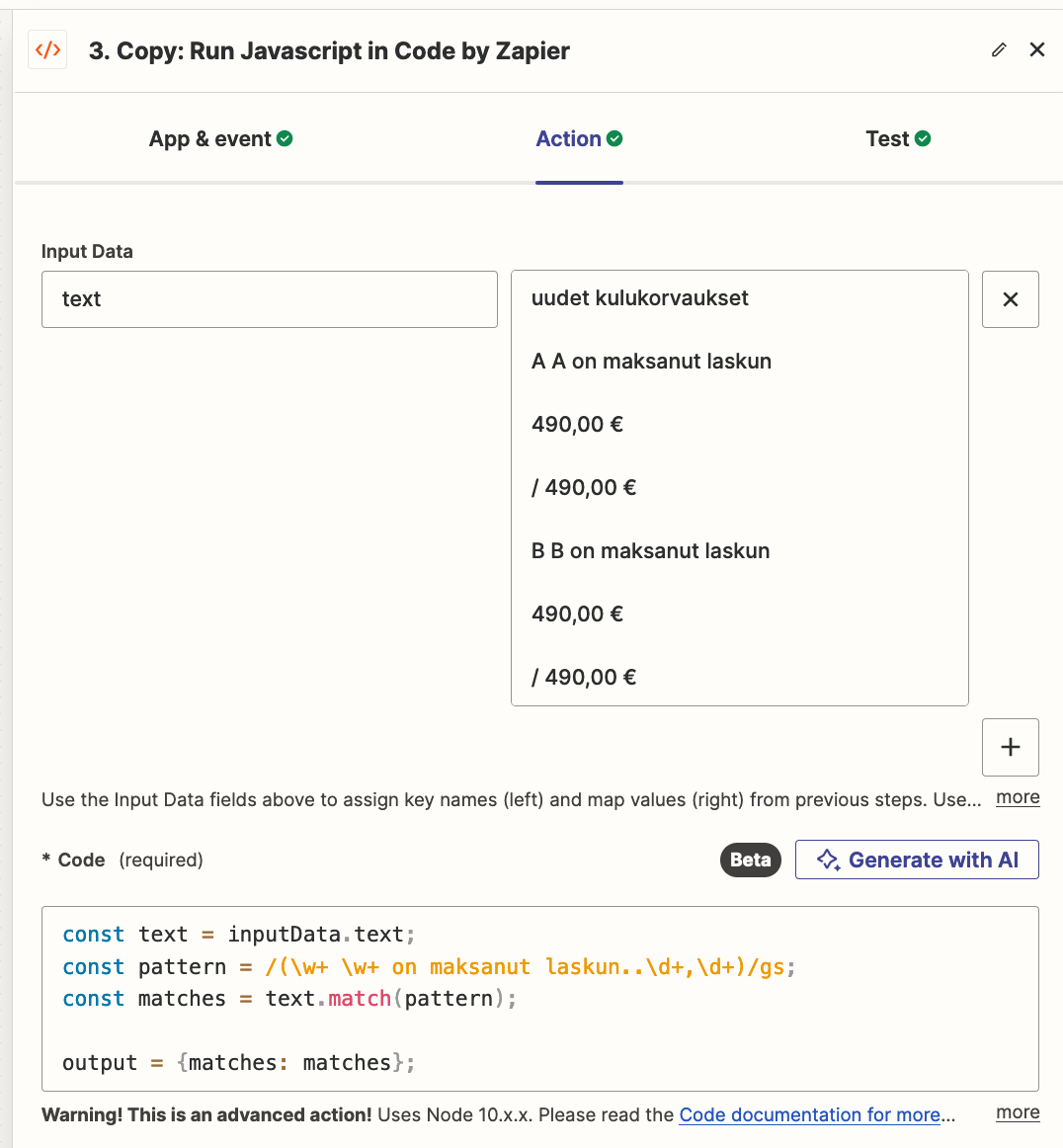
I’m attempting to automate accounts payables reconciliation based on mail statements. The statements can contain n instances of a line (in Finnish) “NN has paid the invoice”.
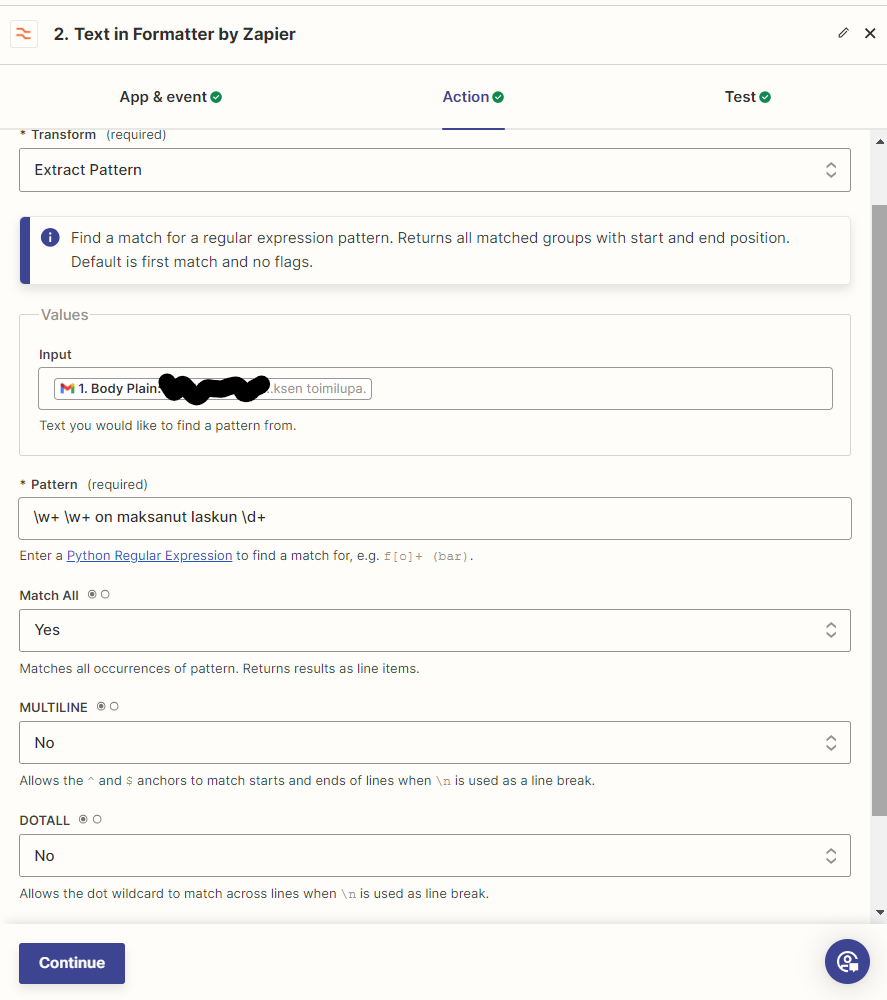
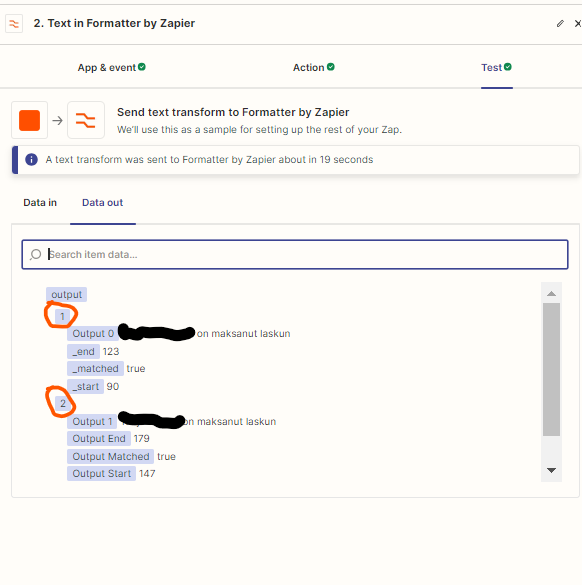
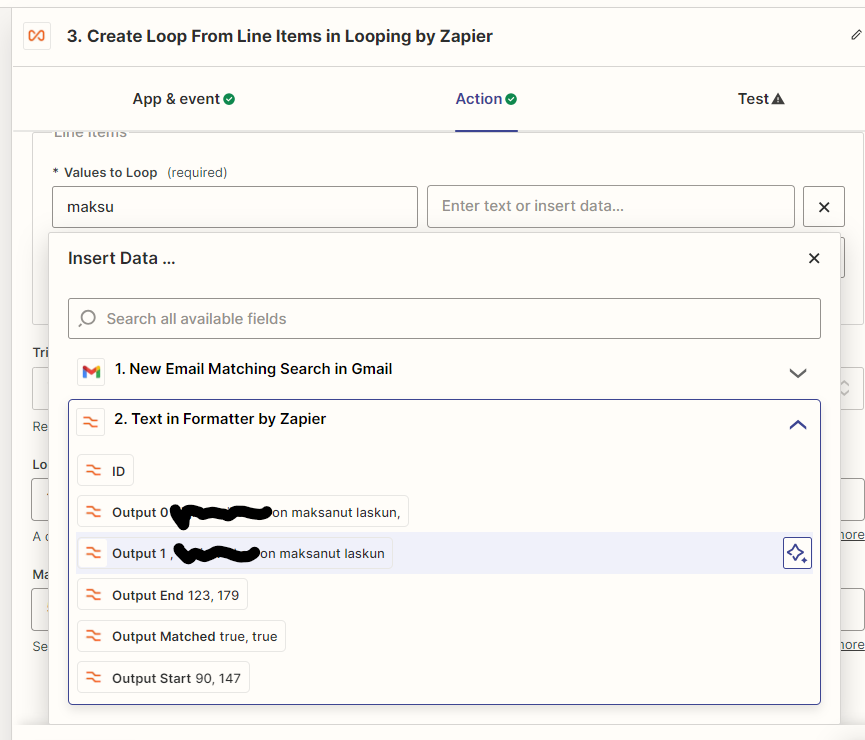
I get the raw text portion of the mail out, and get text strings extracted with Formatter’s Extract Pattern (regexp). The result is a “list” with Output 0...n as shown in the next image.
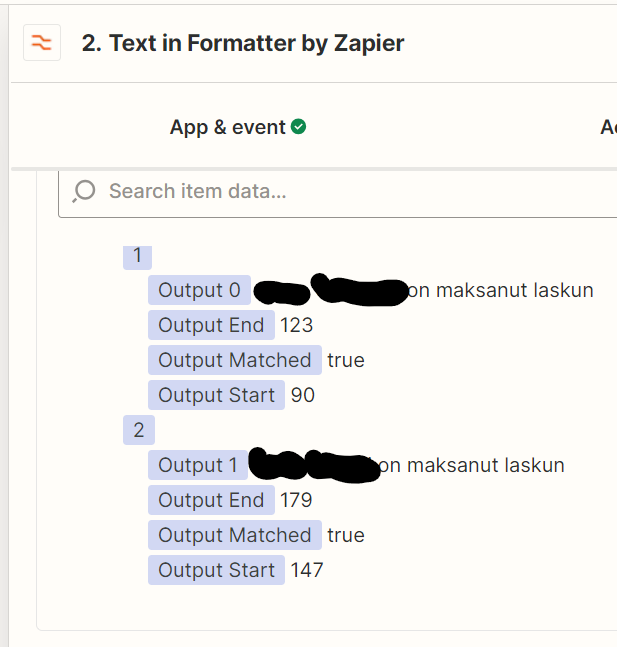
In the next step I attempt to use Loop these to then create a new record for each Output 0...n in Airtable. I have tried both Create Loop from Text and .. From Line Items, but I can’t get either to make sense.
Is there something else I need to do to the outputs I have, before looping them?
Rgds,
Björn