I’m working on a Zap to pull values from a customer-provided PO which contains records of 3 types, indicated by values in a column called “Record Type”. Those values are H (Header), D (Detail) and N (Notes).
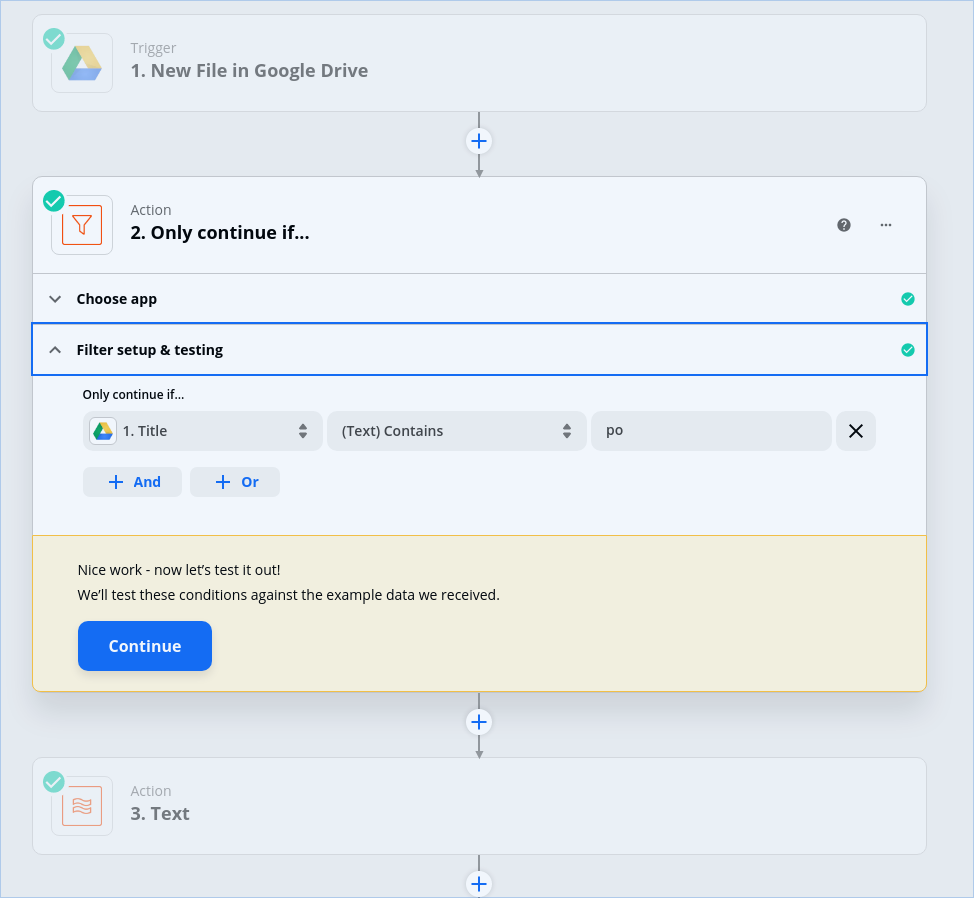
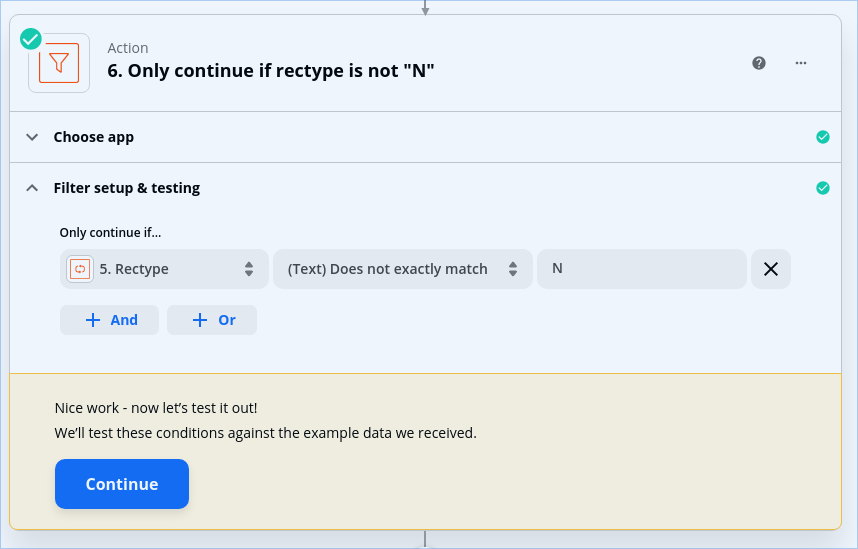
My Zap is working except that it’s trying to process the N line items as if they were D. What I’d like to do is exclude them entirely. Is that possible? Can I basically delete any line item whose Record Type is N?
Best answer by christina.d
Hi there! There’s a bunch of great collaboration here! I wanted to pop in and consolidate some of Troy’s answers here into a single reply:
Okay, that gets me partway there, I think. But it reveals another issue wherein I need to pull data from the H record type to set up the sales order header that I’m creating, but loop through the D records to create order line items.
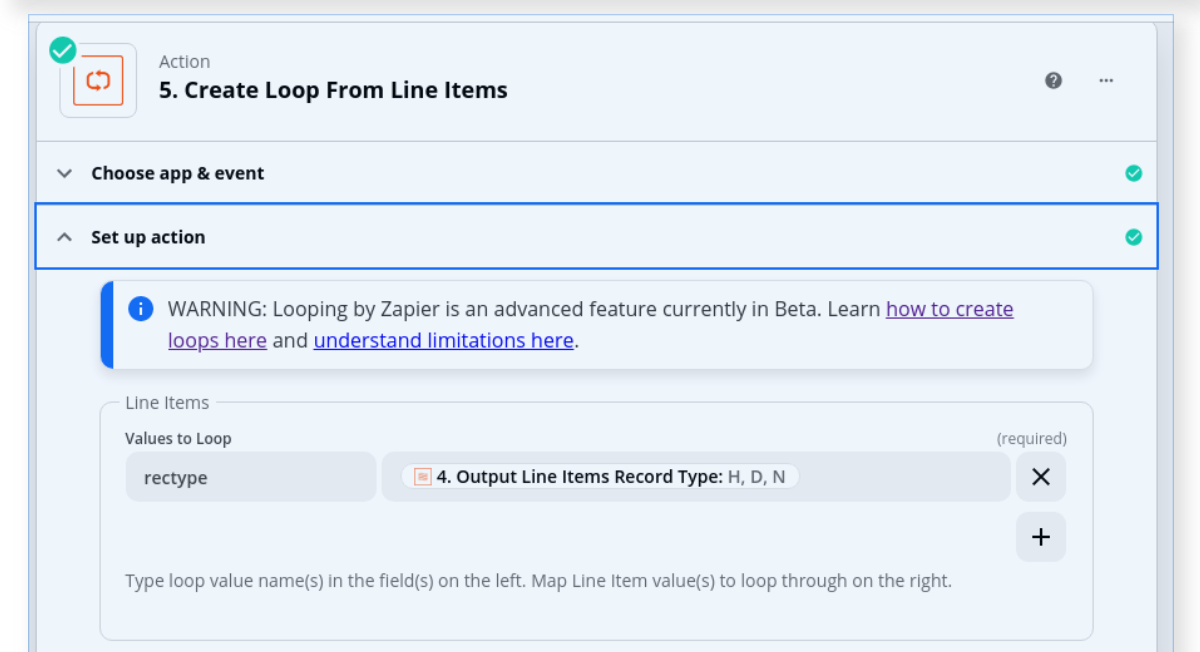
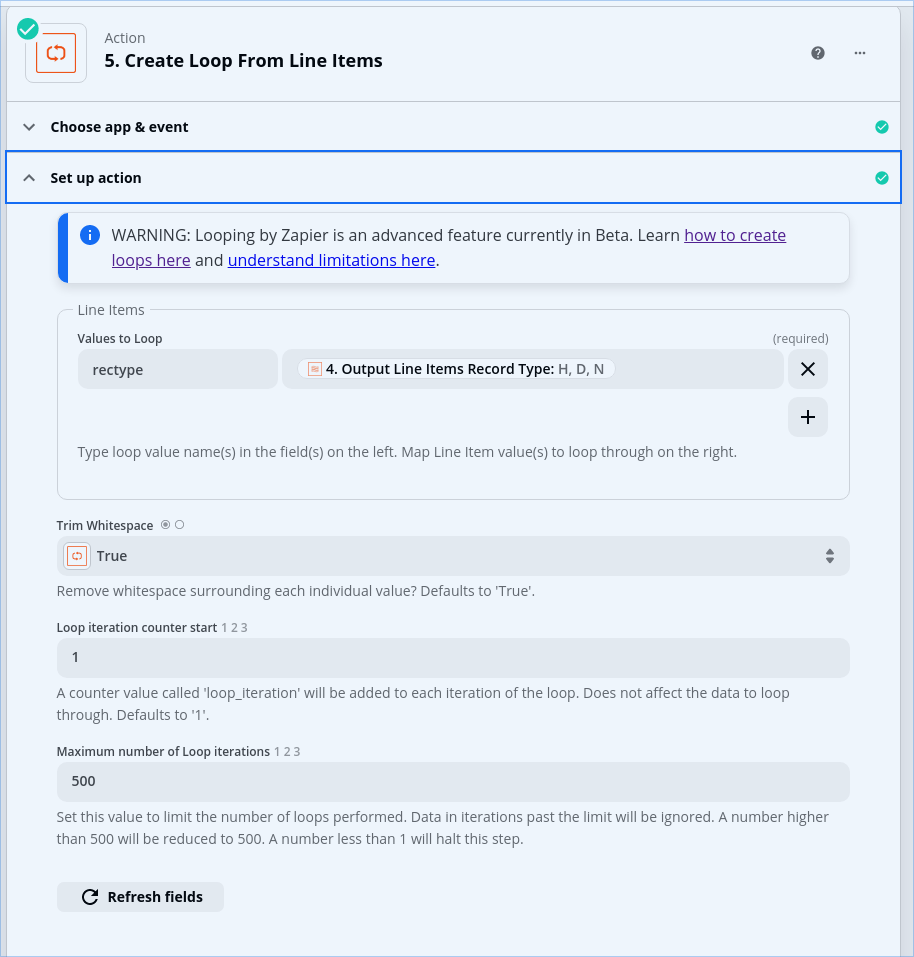
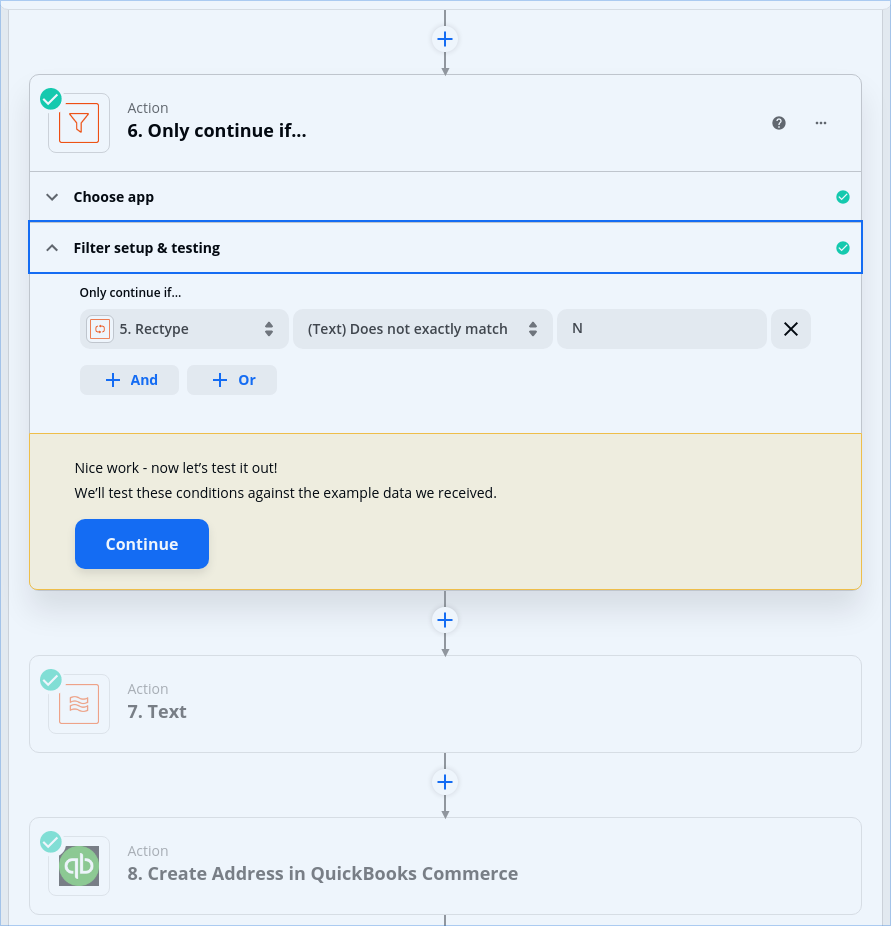
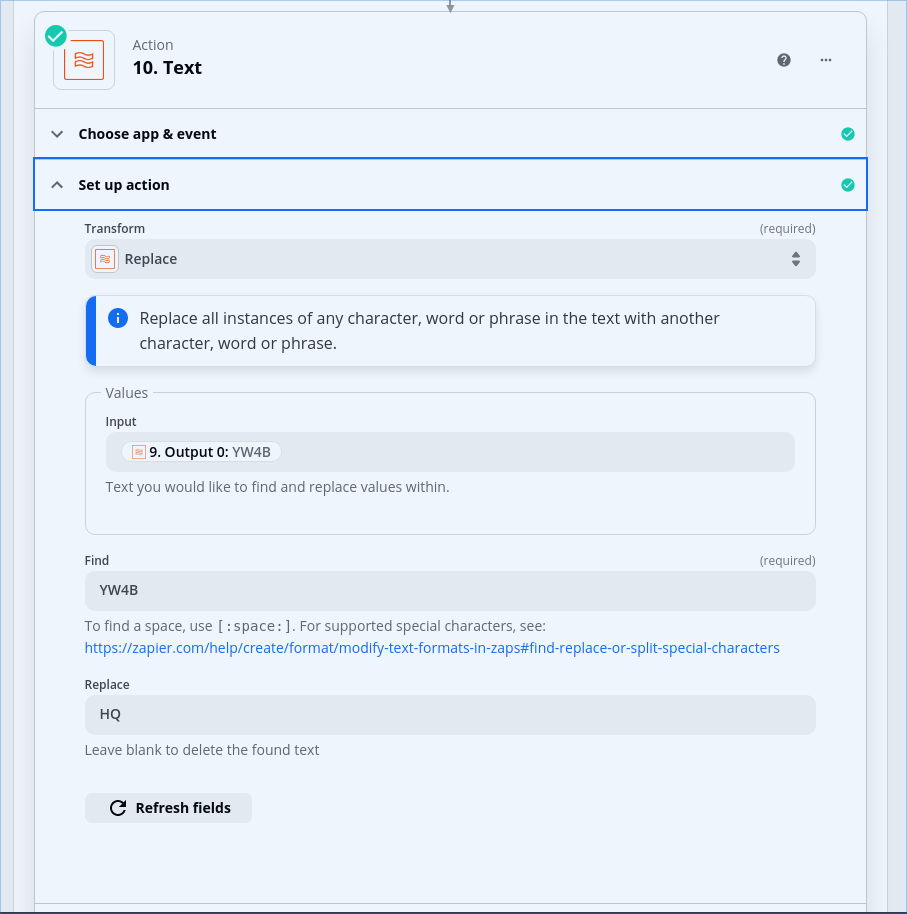
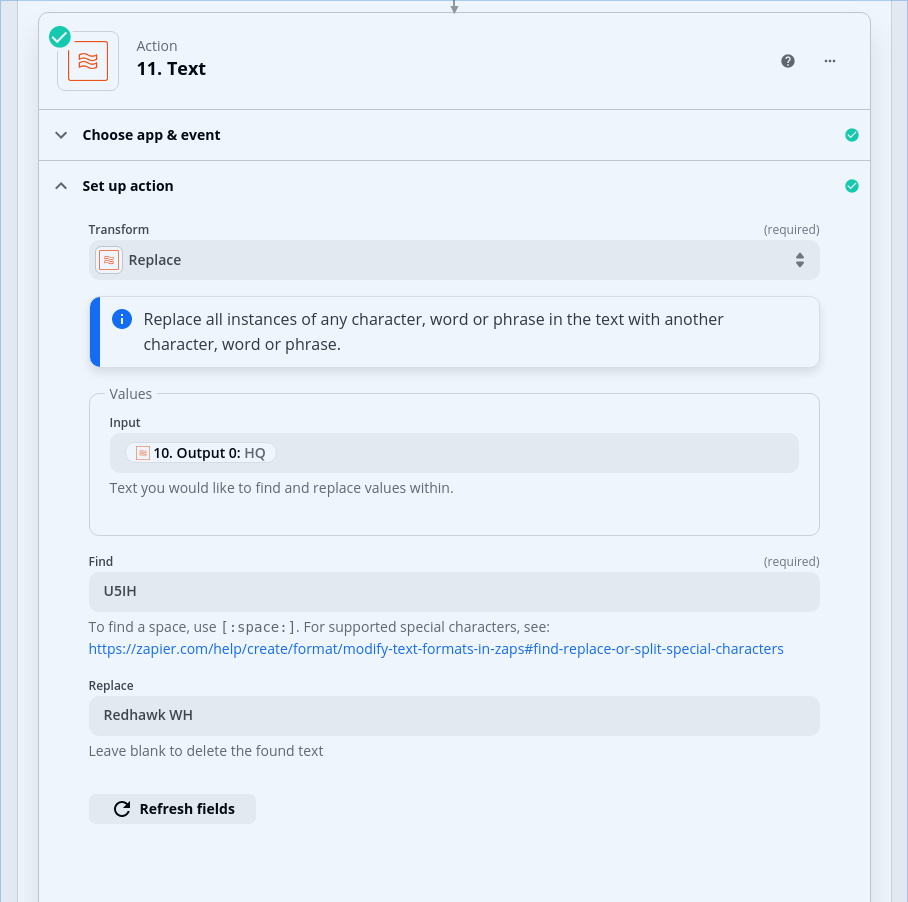
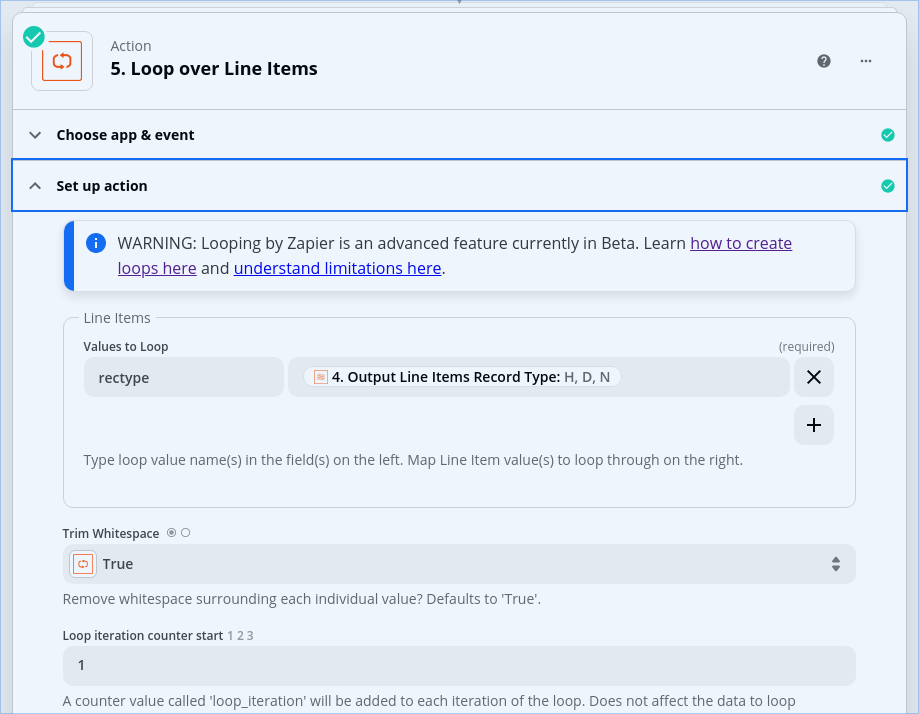
I set up my loop to reference the record type column and map it to a “rectype” variable. I added a filter as the first step in the loop to exclude any record with a rectype of “N”.
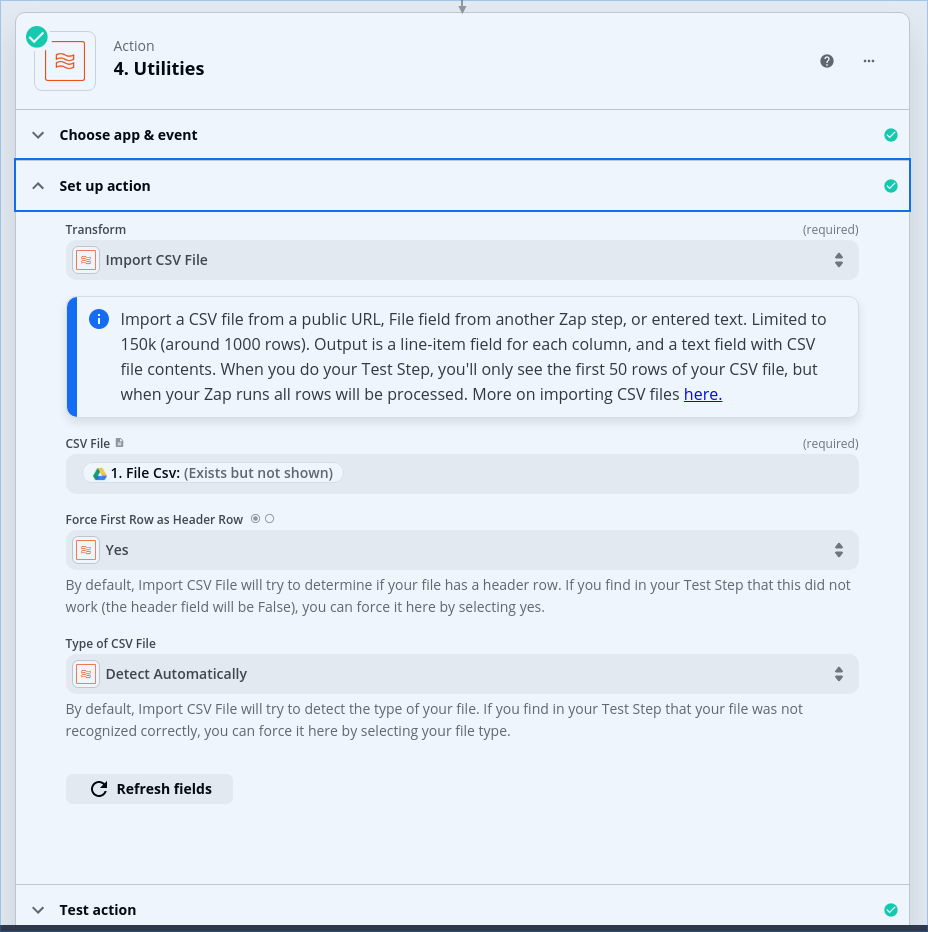
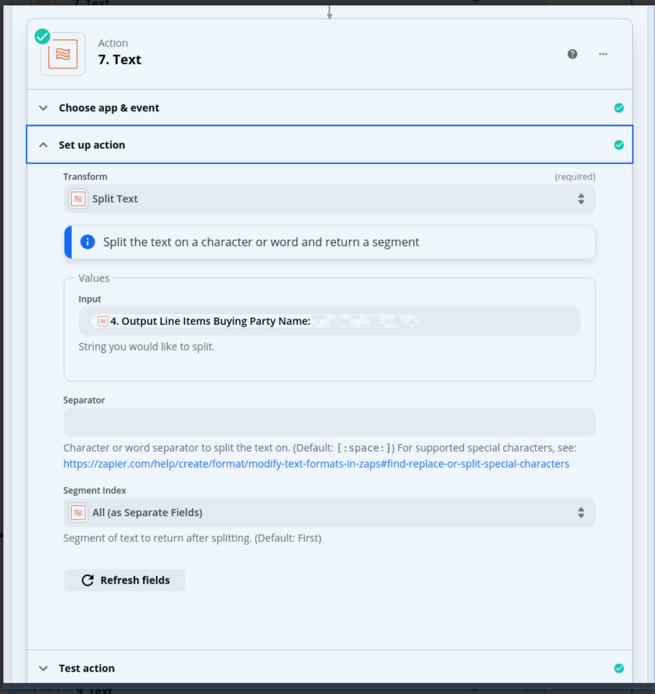
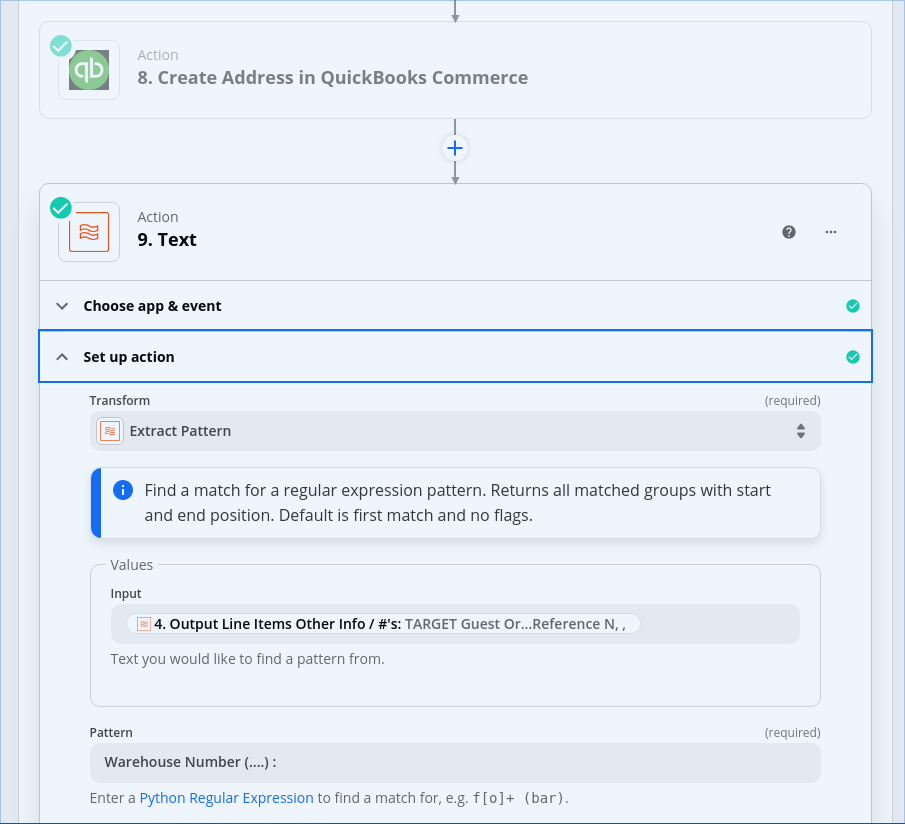
In subsequent steps, I’m referring back to the data values in the Utility step which read in the CSV. Is that correct, or do I need to map all the columns in the loop step so that I can reference them there?
Here are some screenshots that I hope give enough background. I tried to capture the most essential bits but may have missed some.
This post has been edited by a moderator to remove personal information. Please remember that this is a public forum and to remove any sensitive information prior to posting.
Absolutely, and it’s highly possible I’m missing something obvious. This is the most complicated Zap I’ve tried to write so far.
The input CSV has 3 lines in it. The first is the H row and contains all the ship-to and bill-to information for the order.
The second is the D row. In this case, there’s only one, and it contains the SKU ordered, price, and quantity.
Finally, there’s a single N row, which contains notes which don’t matter to this Zap at all.
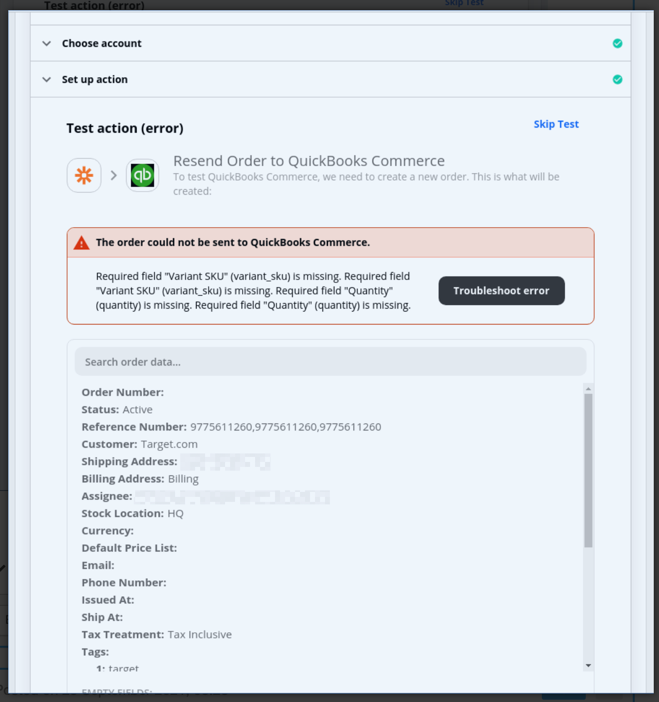
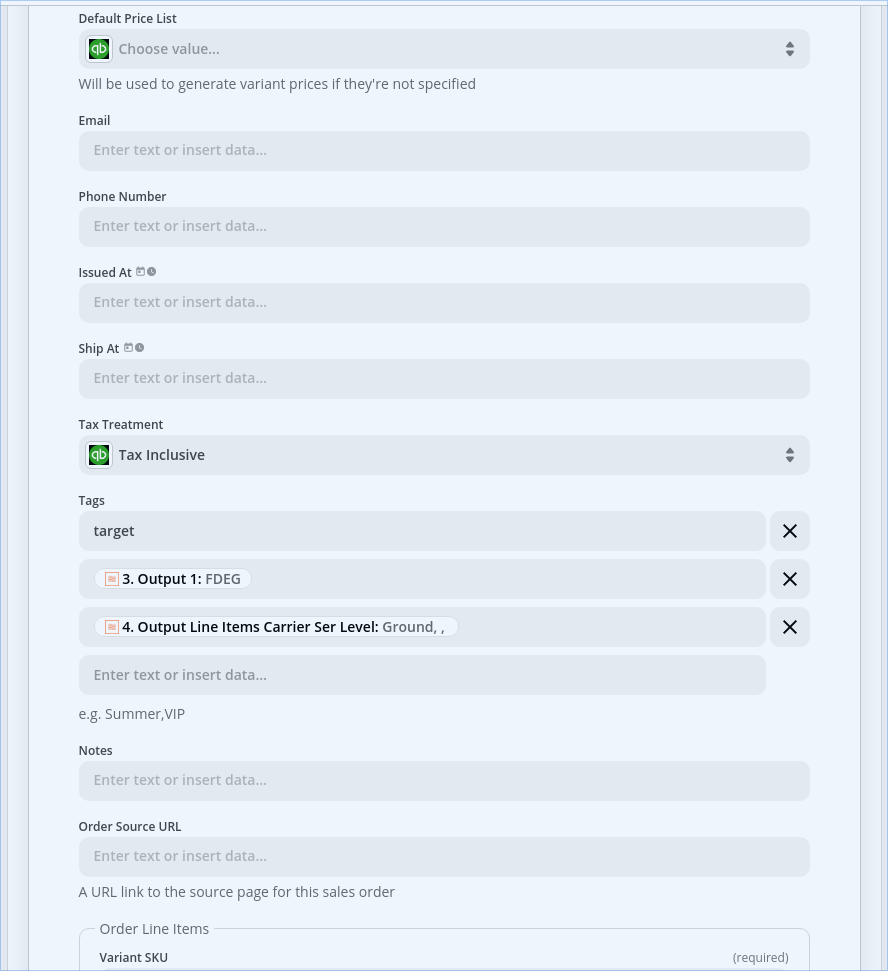
These all share column headers, so there are lots of blanks. The SKU column doesn’t have a value in the H or N rows, and the ship-to has no value in the N or D rows. So I think the error is either coming from the D row not having a SKU value, or the N row not having a SKU value.
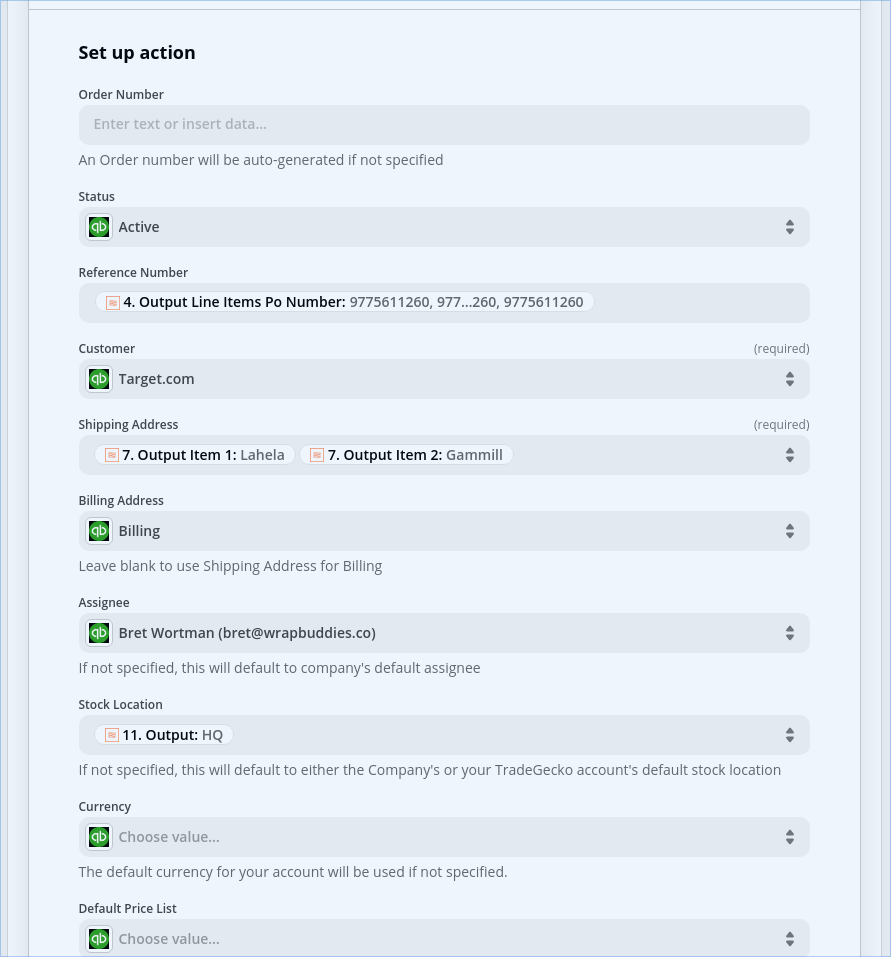
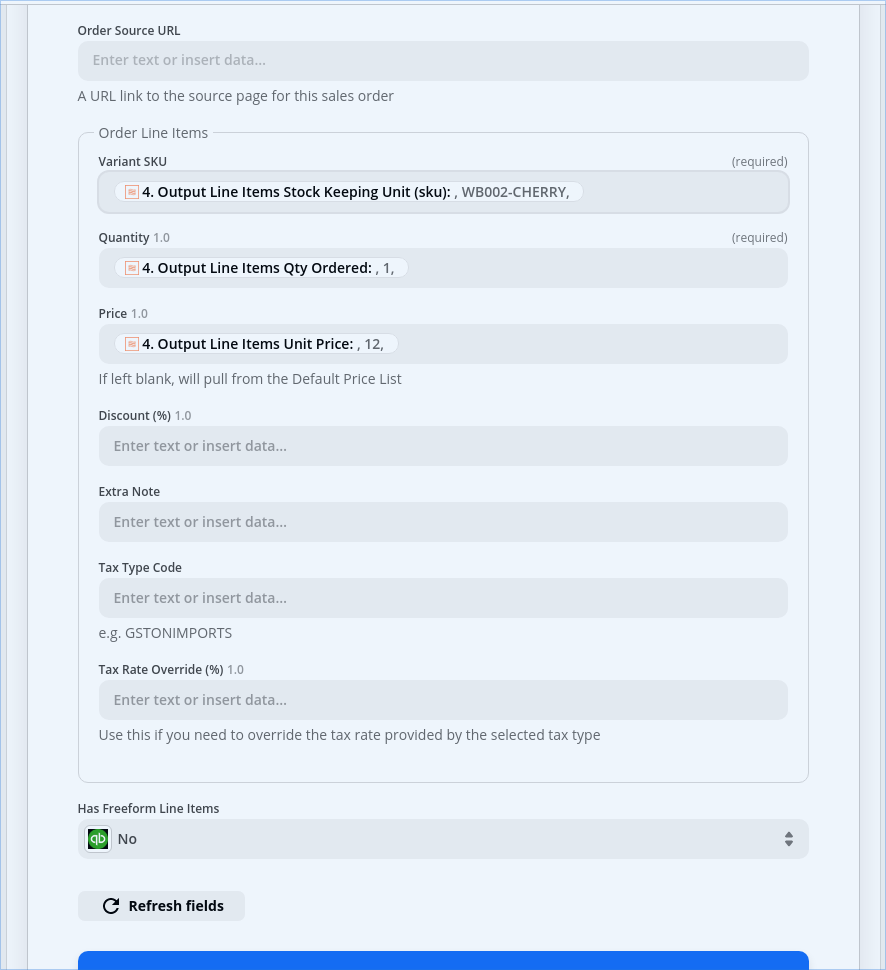
Within the order creation app, there are order-specific items which I’ve been able map from the H row, and then the order items are added, one per line item (specifically, one per D row).
And when I say H, D, or N rows, these relate to the values found in the “Record Type” column of the CSV file.
Can you show us actual data using screenshots, rather than hypotheticals? For example, from H row I’m trying to extract these data points and map those to these Step #s.
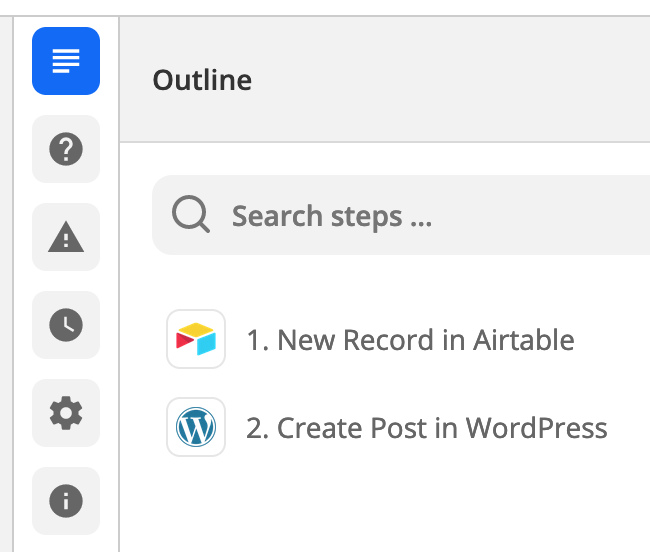
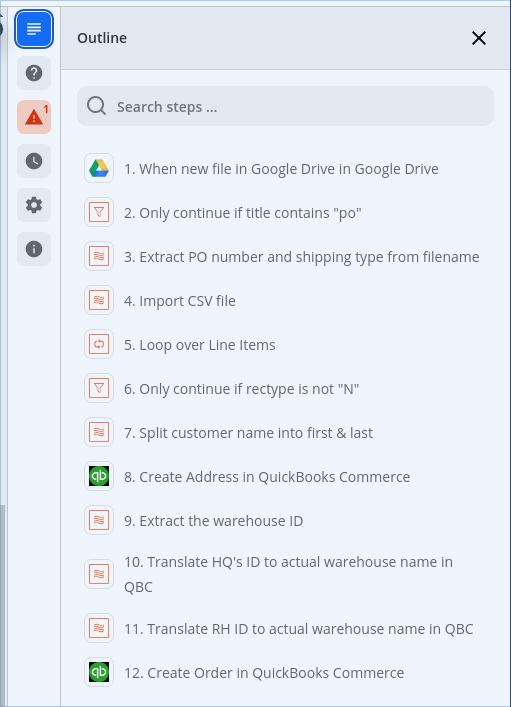
Can you post a screenshot of the Zap Outline Steps from the Zap Editor right rail? (see example below)
NOTE: It’s a good idea to relabel Zap steps to indicate their purpose.
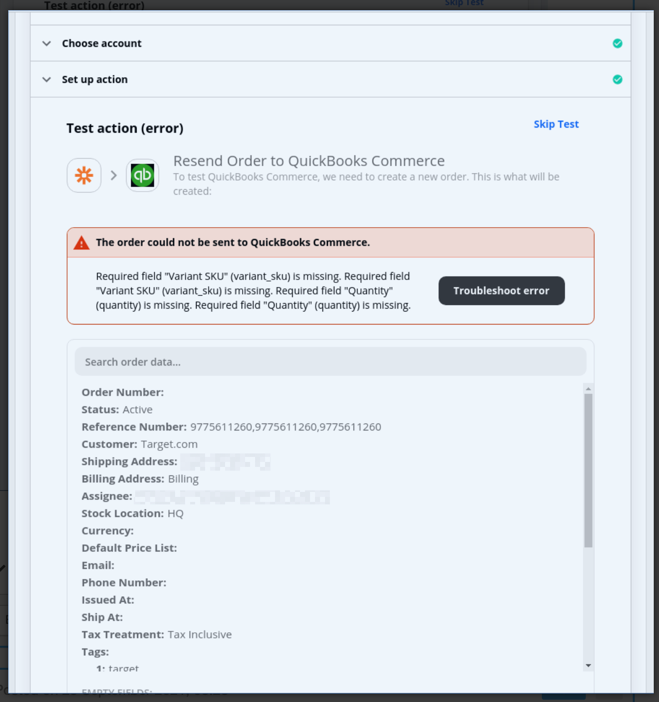
Also, this screenshot doesn’t show how the Zap step is configured. Error indicates a mapped variable is missing, which could be due to how you are trying to test.
Let me get on that. I’m learning a lot already -- didn’t realize I could relabel the steps. I should have guessed. I’ll post updated screenshots here shortly, and a better description.
Okay. Here’s the overall Zap, now with explanatory step names:
The source data looks like this (masking the customer’s data for privacy reasons):
Past this, there’s just the company billing information and some other columnss which aren’t used.
So what I need to do is pull out the customer information from the “H” row and use it to populate the order header. The order detail needs to come from however many “D” records there are, in this case just the one, in which she ordered 1 unit of WB002-CHERRY at a price of $12.
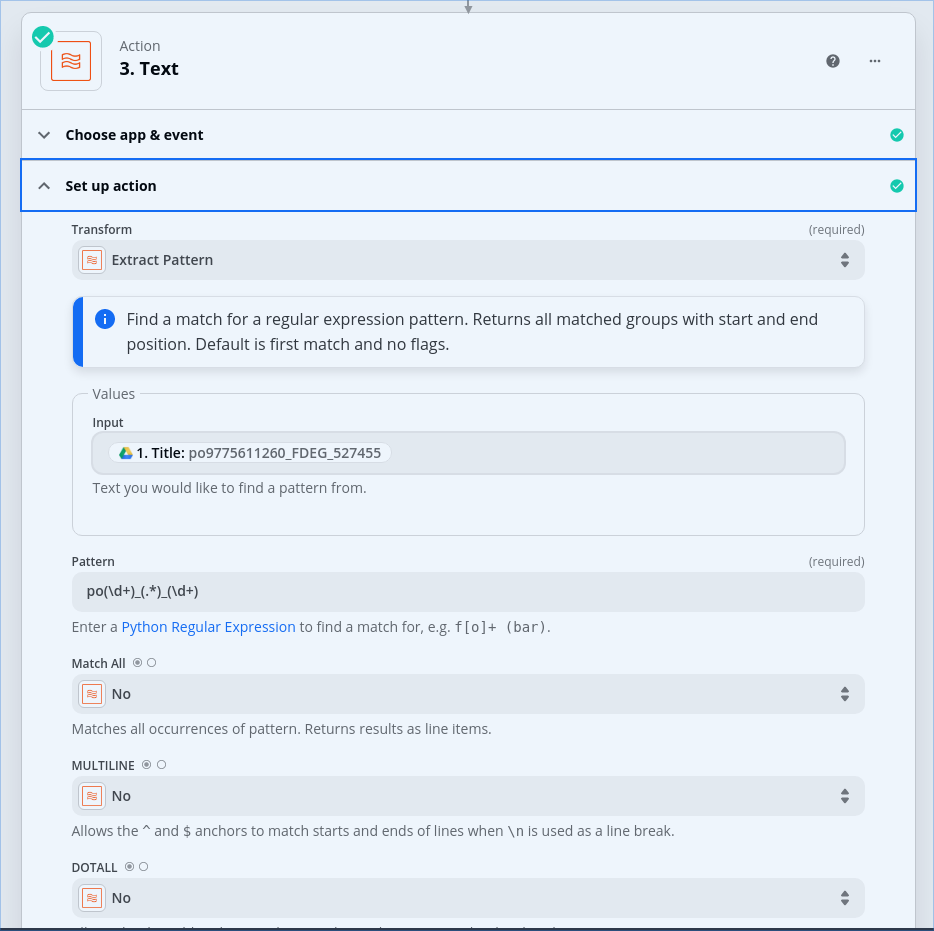
Sorry, the record type column is column AC, and it’s being extracted like this:
In Column AC, the header row give the name “Record Type” which is used there from step 4 (where we are using the force first row to be a header row option).
This feeds into the filter which excludes the N record type:
I had thought about just using a Python code step to turn all this into a data structure that could be used later. I think that might be the easier thing to do. It’s more familiar to me, anyway.
For the QBO Create Order step, it’d be helpful to post screenshots of how that is configured with the mapped data points.
The screenshot of the CSV data doesn’t show which the Record Type column so unable to determine which row is H/D/N.
If you are trying to use data from the header row across 1+ D rows from the CSV, then you may need to handle that data before the Looping step
You may need to pass all CSV fields into this step in order to use each field of the line item in future Zap steps.
Alternatively it may make sense to try to use a Code step (advanced) to handle the data prep from the CSV file: https://zapier.com/apps/code/help
and finally:
@wortmanb
If you know code, then use Code as it was save Zap steps (and thus Tasks), while allowing for more advanced logic and data handling.
The Zappy Awards are back
We're celebrating the Zapier builders making AI transformation happen. Winners get a published story on zapier.com, a trophy, $5,000 cash, and a feature at ZapConnect. Nominate yourself or a peer by July 24th, 2026.