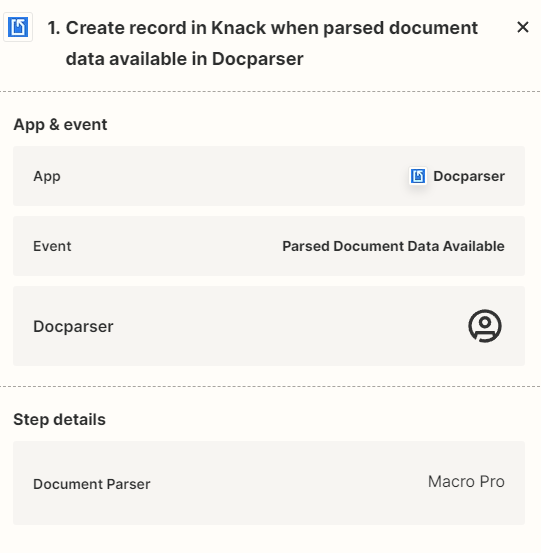
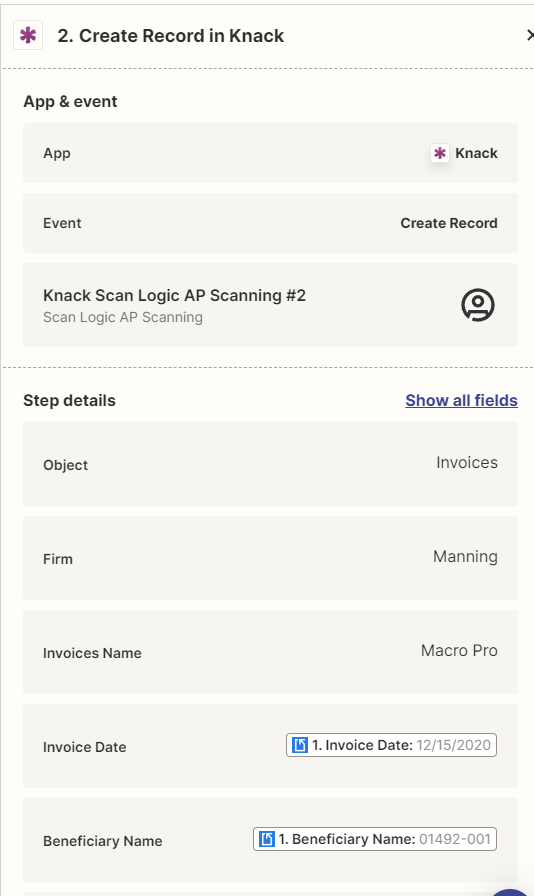
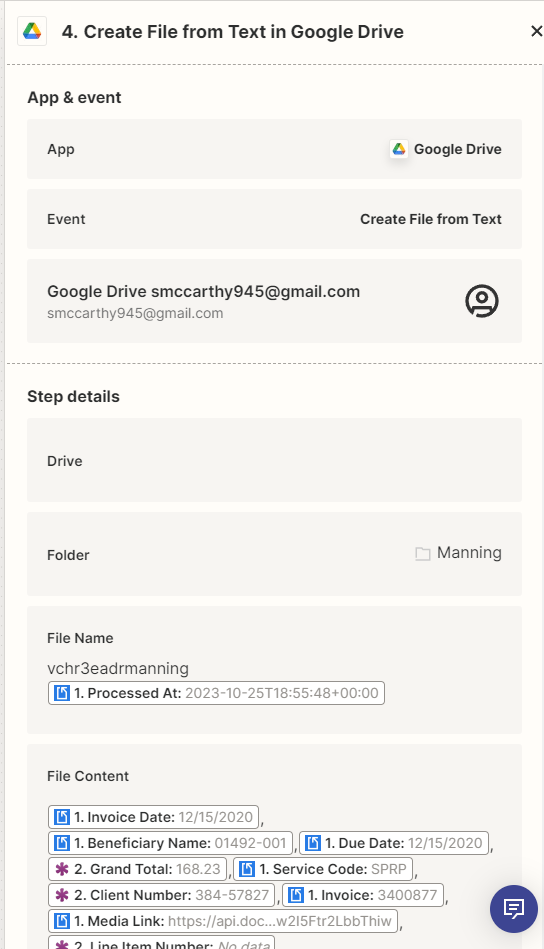
I am trying to create a ZAP where I retrieve scanned documents from Docparser, save the PDF to Google Drive and then create a CSV file in Google Drive from the records created in the Knack DB. I am creating the Knack DB records when Docparser scans the files.
I have everything working except creating the CSV. When Zapier writes the CSV to Google Drive, it creates a separate CSV file for each record. I am trying to get it to write multiple records into the same CSV file so I can use the CSV to load records into another system. I have tried EasyCSV and Google Drive create CSV and they always write 1 record per CSV file.
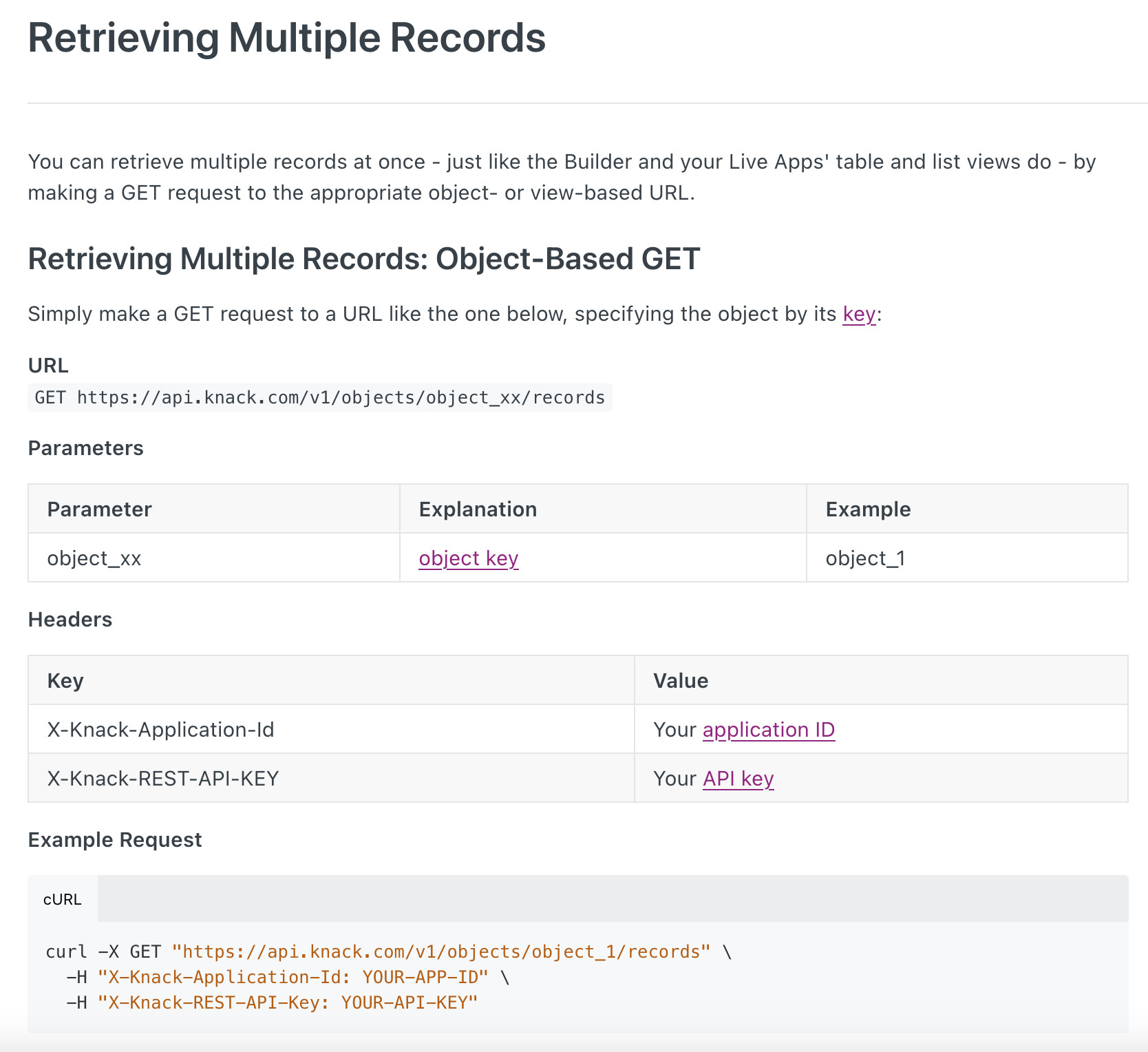
I am trying to figure out how to get multiple records written to one file. I just need to grab all records from Knack where the field called CSVCREATED = N. I have tried doing a Knack record lookup but that doesn’t work because you can only lookup by the record ID #. I understand a loop may work but not completely sure.
I am simply trying to read multiple records from a Knack table where CSVCREATED=N and write those records to 1 CSV file. Can someone tell me how I can accomplish this?
Thank you in advance.