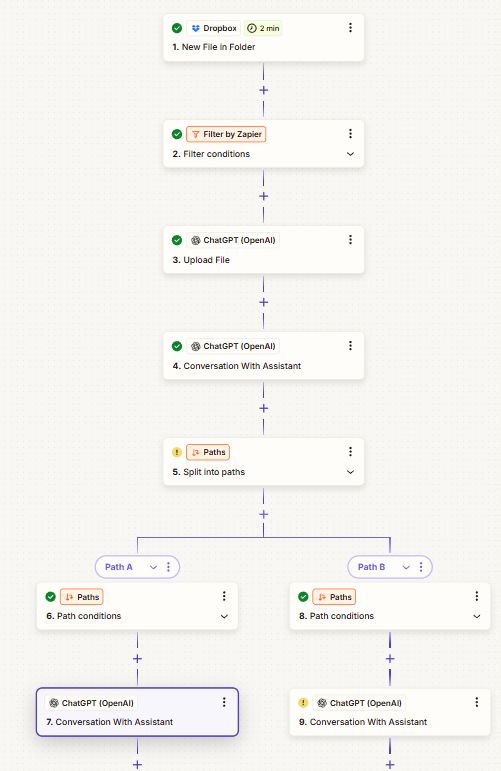
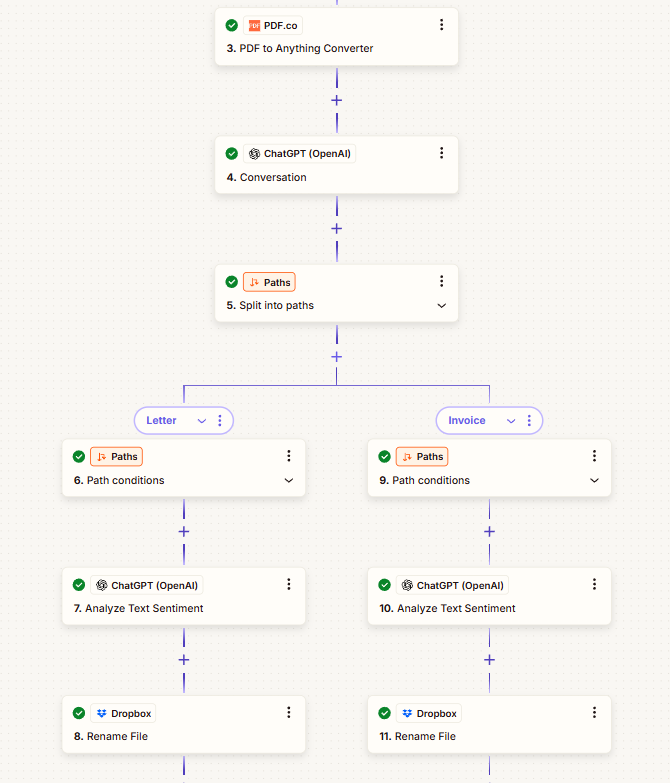
I need to automate the process of reading and renaming PDF scans uploaded to Dropbox. The PDFs are either invoices/bills from various vendors or official letters (mainly from tax authorities). The goal is to:
- Detect a new file upload in Dropbox.
- Extract content from the PDF.
- Rename the file based on its content using the formats:
- Invoices/Bills:
<invoice_issuer_name>-<invoice_number>-<invoice_date>.pdf - Letters:
<short_letter_subject>-<letter_issued_date>.pdf
- Invoices/Bills:
- Save the renamed file in Dropbox.
I currently use Dropbox + OpenAI + PDF.co via Zapier, but parsing is messy and inconsistent due to varying PDF formats. Is there a better, more reliable way to automate this process? Any tool or workflow recommendations would be appreciated.
Thanks in advance!