Hi Zappers,
I am wanting to fully automate my LinkedIn prospecting and emailing process to cold leads. I use Phantombuster to
- Automatically Connect with Linkedin users
- Scrape those users’ emails using Phantombusters discovery service (max 20 emails per day)
I want to automate the import of my leads information into Snov.io, so that I don’t need to constantly import CSV files.
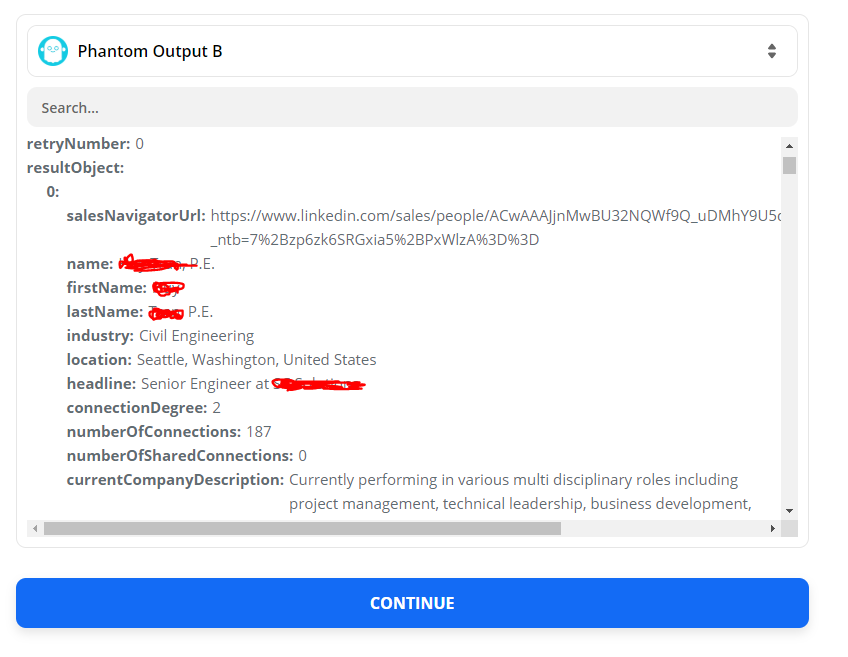
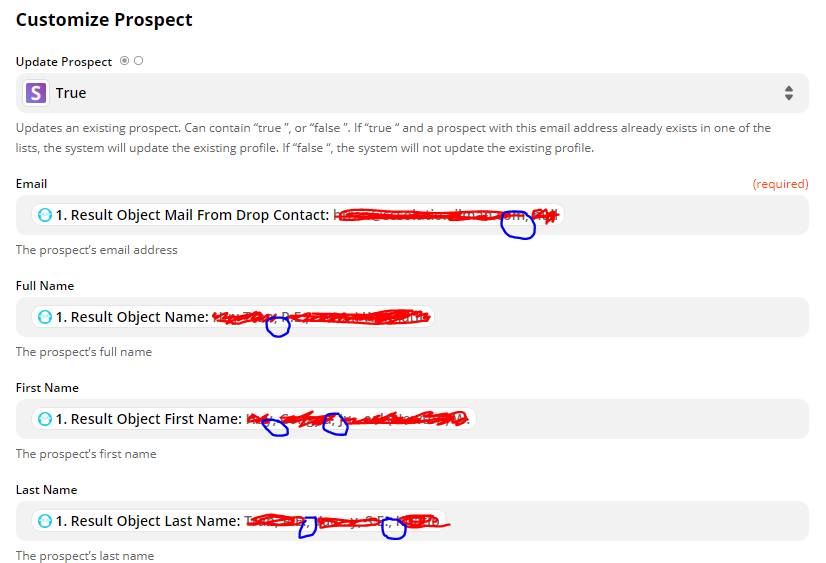
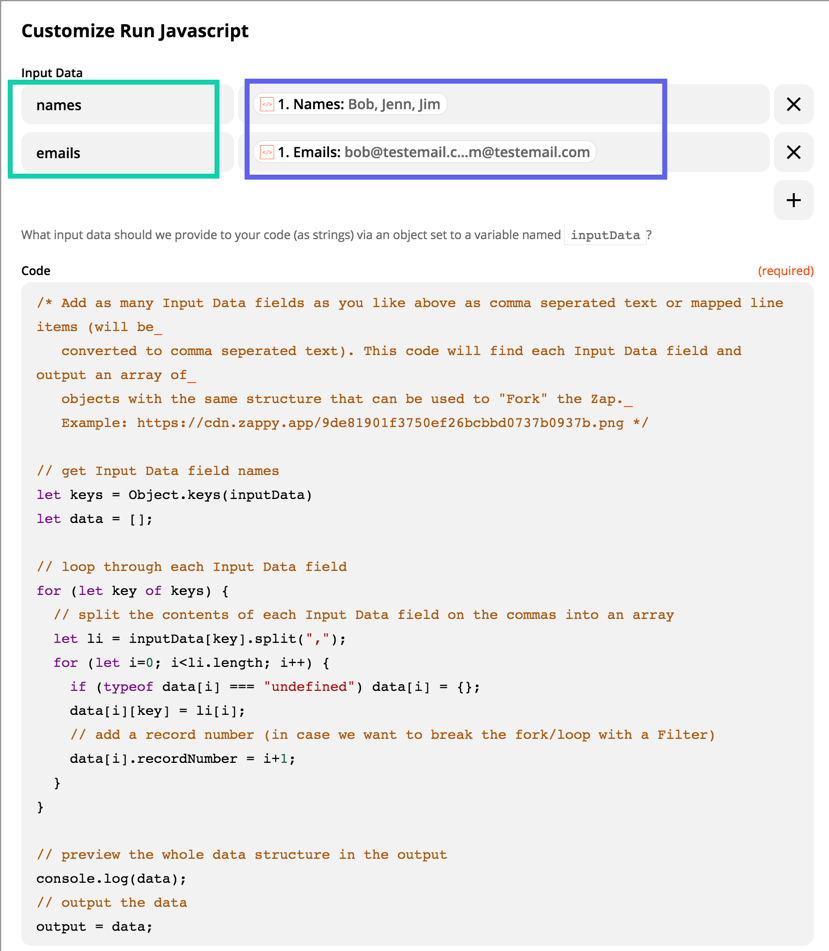
Setting up the Zap between these two apps, I don’t have an issue filling out or mapping the information, but I am getting errors because the JSON object contains every single email/lead that I had scraped in the most recent Phantom that was run.
Other than changing my Phantom to run just a single email per launch, is there a way to get around this? Or are Zaps only able to handle one set of information each run?