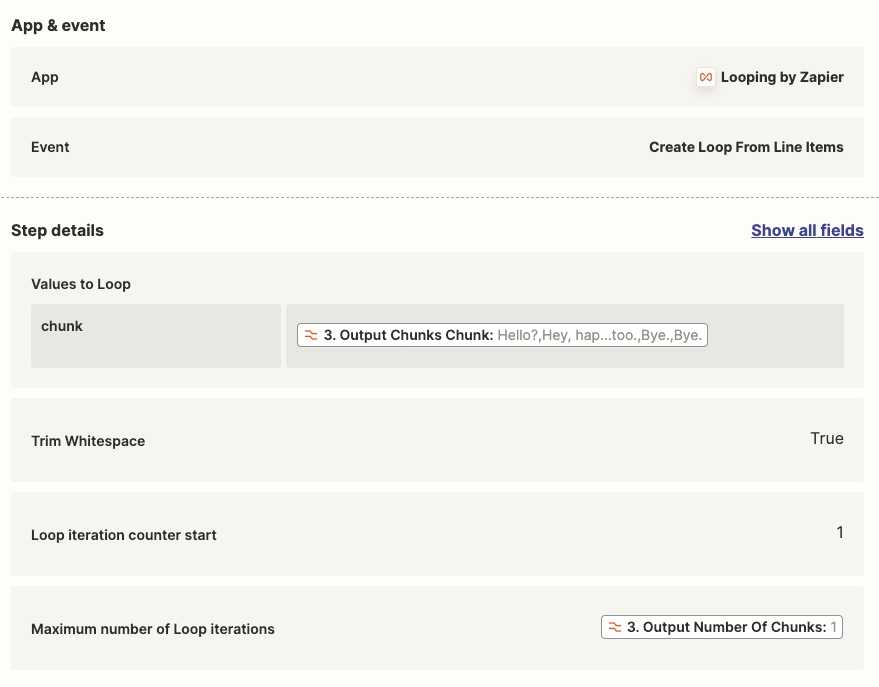
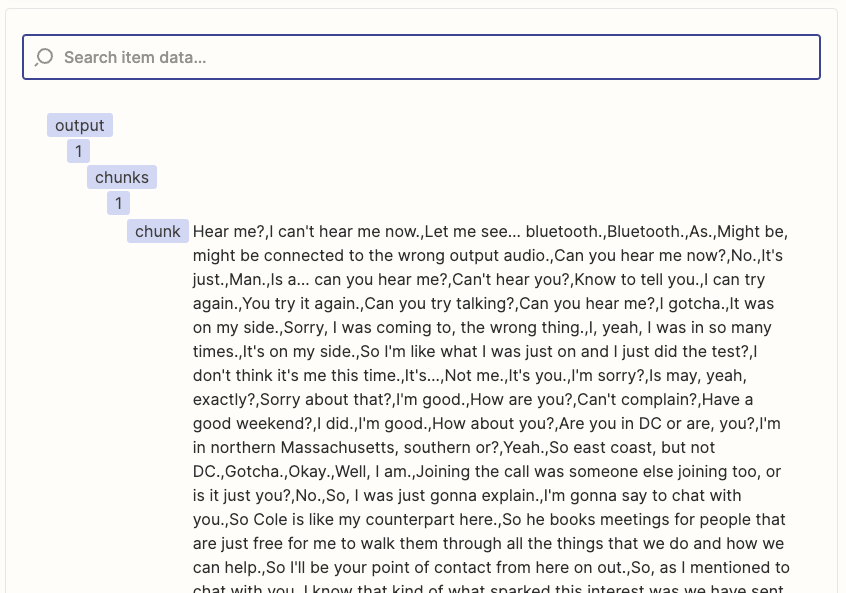
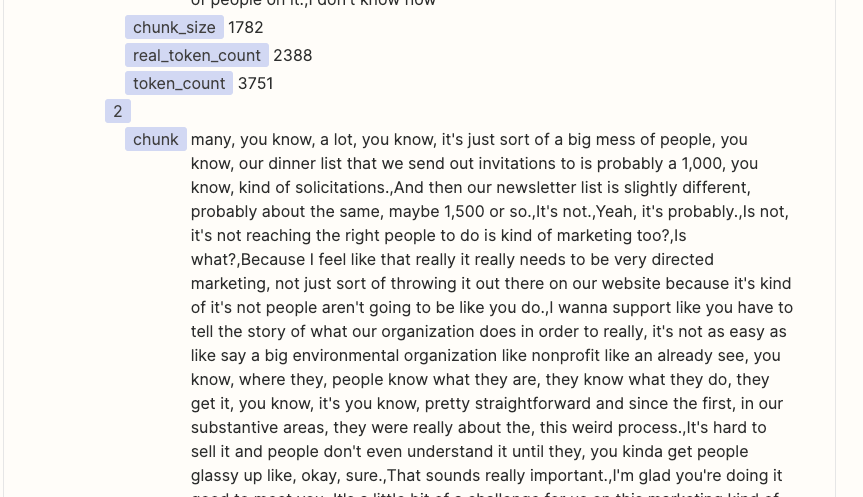
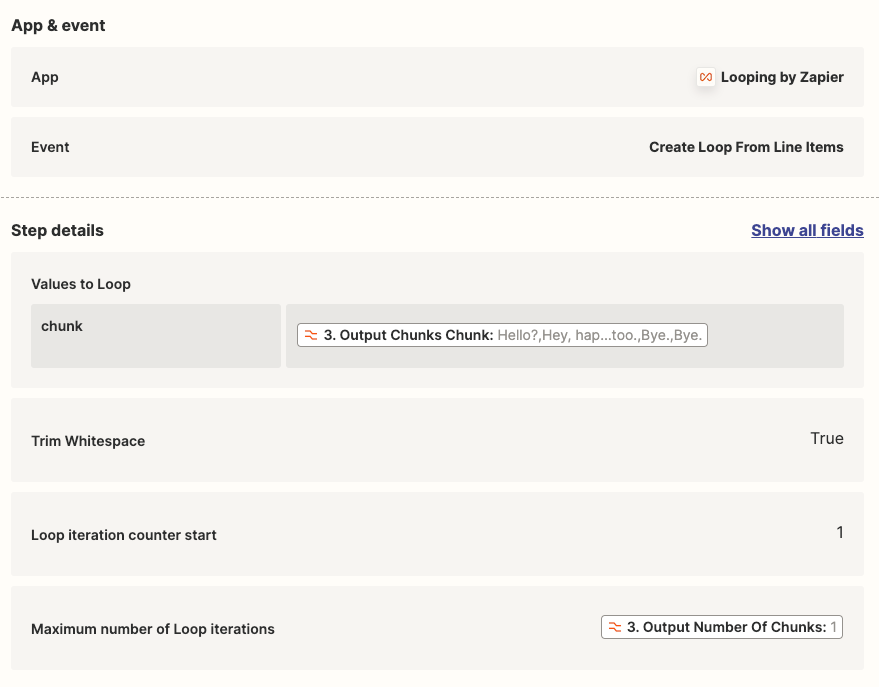
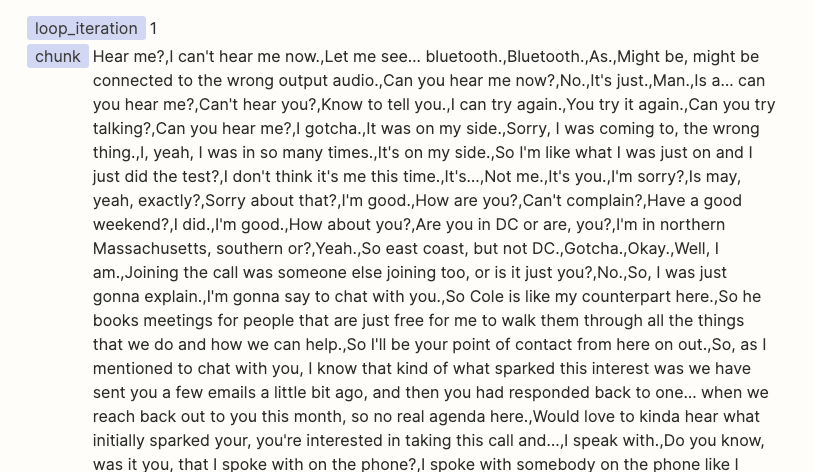
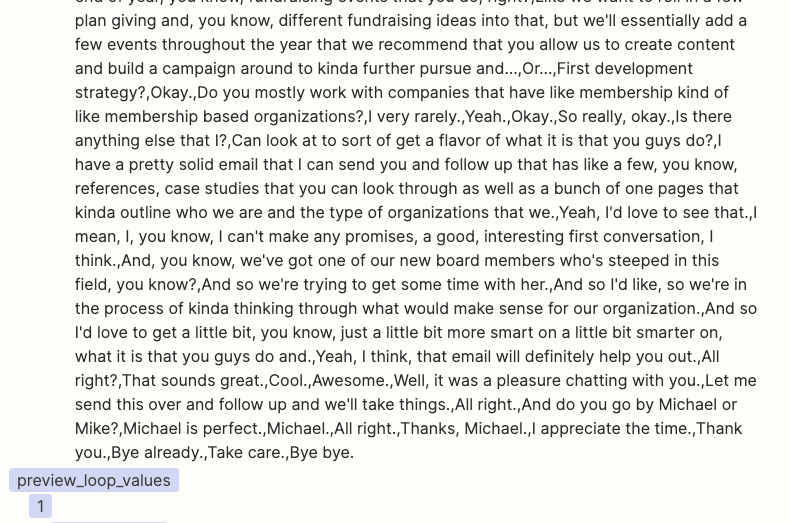
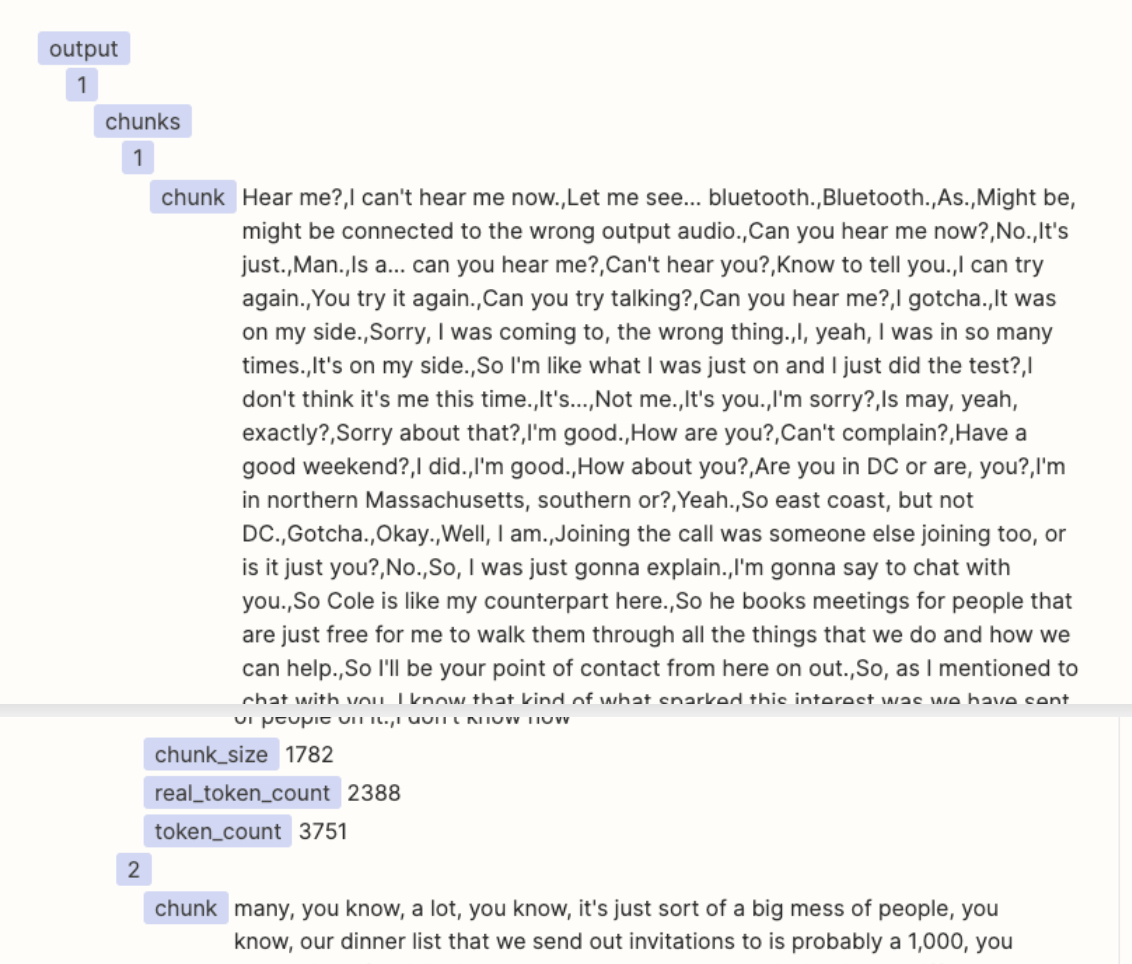
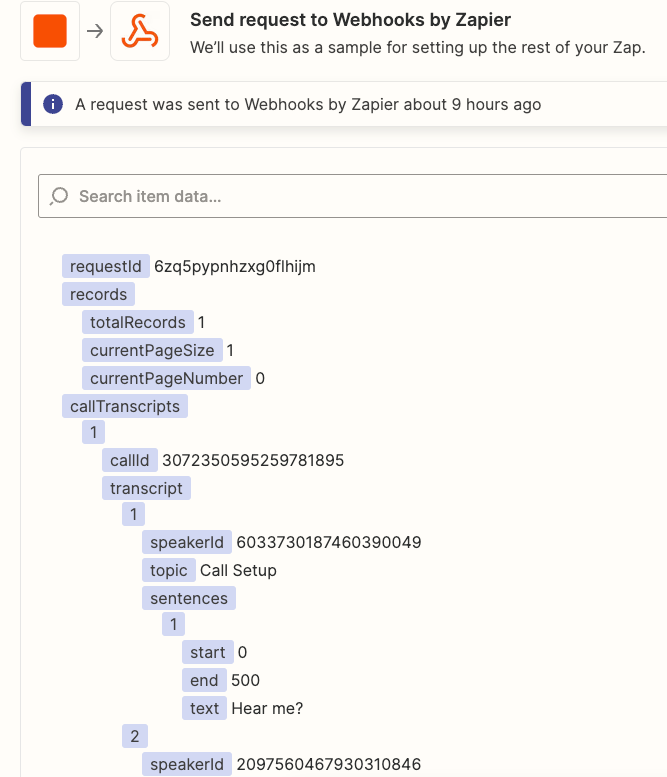
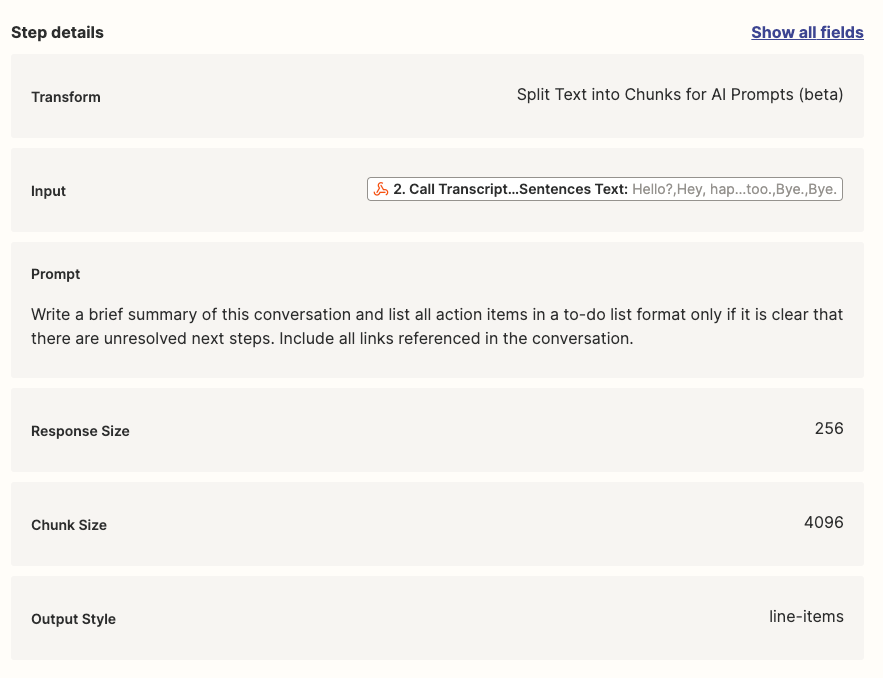
I have a Zap to summarize Gong Call Transcripts through OpenAI. I am using the ‘Split Text into Chunks for AI Prompts (beta)’ in Formatter to chunk the transcripts into a size that fits the OpenAI token limit. I can see in the Formatter Results that it is successfully ‘chunking’. However in the subsequent ‘Looping’ step, the ‘Output Chunks Chunk’ from the Formatter step is not being delivered as a ‘Chunk’, it is still the entire transcription. As a result I am not able to run the Flow into OpenAI as the prompt exceeds the token limit.
What am I doing wrong? See screenshots below for the current setting of the ‘Formatter’, and the ‘Looper’ step next. I am trying to follow the Zapier-provided template for OpenAI chunking of large form text.
Formatter screenshot:
Looper Screenshot: