
Hello everyone,
i need your help.
Im trying to download muliple files such as .jpg .png .mp4 to my OneDrive via Zapier. As Im aware that there are no standard functions within Zapier that allow me to do so, me and a friend coded a python script that should do the job. Unfortenatly it somehow throws us some errors.
The input data we give the code is an array of multiple links we extracted through a javascript beforehand:
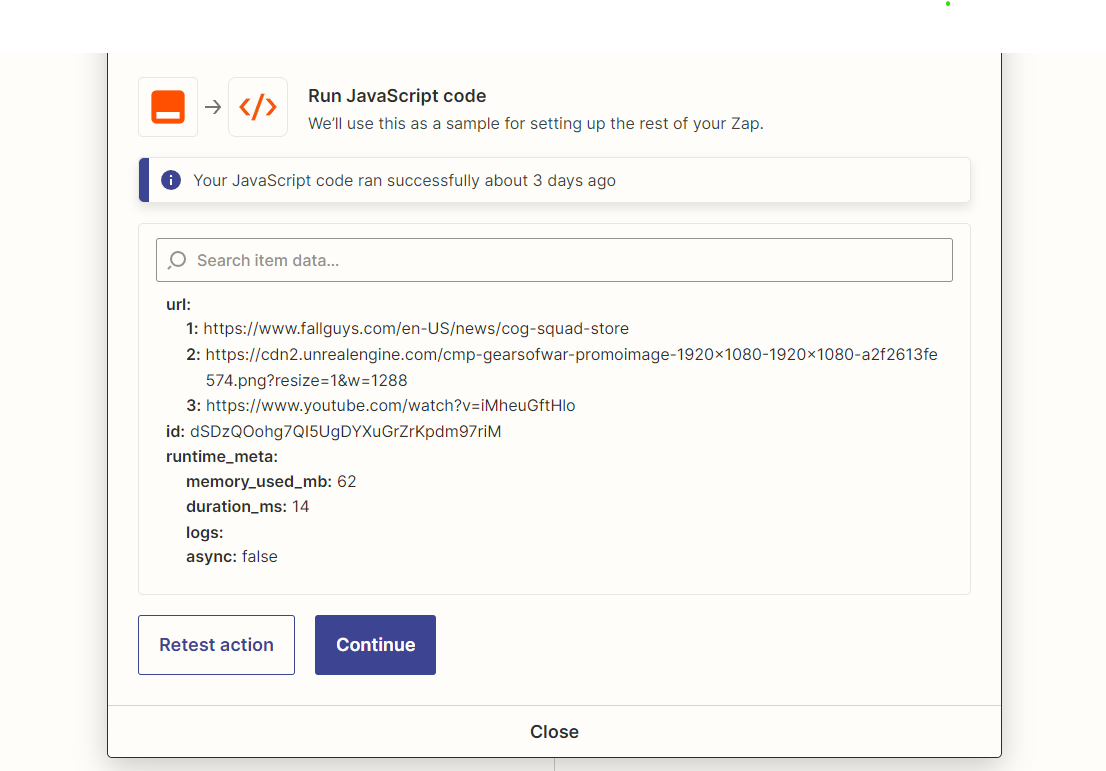
We extract these urls from a .csv document.
We then use this array in our code which can be seen here:
! We use a OneDrive dictionary path as one of our variables. The “path” variable is getting passed by one zap before the script which in this case is: “/Data/Extractor/Fall%20Guys/Fall Guys - 12_11_22 06-45PM”
The second variable is the array of urls, which contain these three urls:
- https://www.fallguys.com/en-US/news/cog-squad-store
- https://cdn2.unrealengine.com/cmp-gearsofwar-promoimage-1920x1080-1920x1080-a2f2613fe574.png?resize=1&w=1288
- https://www.youtube.com/watch?v=iMheuGftHlo
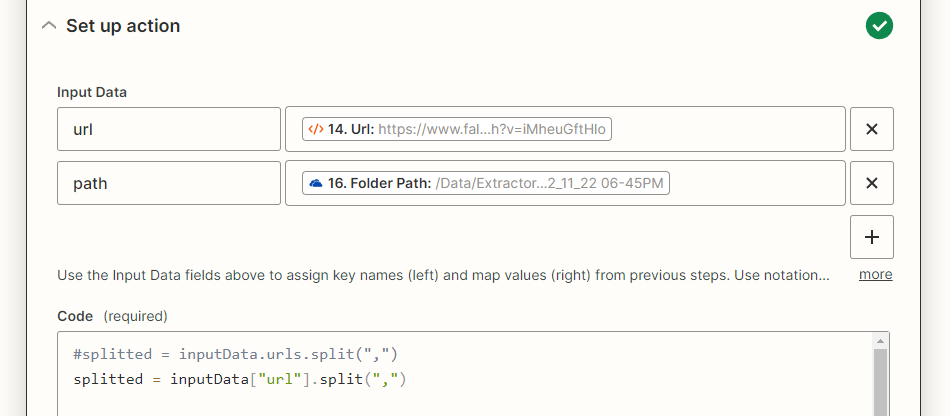
What the code is doing is:
- Splitting the urls of the array for each “,” there is
- Analysing the file format
- Downloading and Uploading it to the path
Possible errors we could think of would either be:
- Functions such as “check_for_image” or “check_for_video” do not work because functions are unsupported within Zapier’s python Script
- We need an access token generation which lets us access the OneDrive Folder via the script (as seen here: https://www.youtube.com/watch?v=Ok8O_QnrSBI)
- Somehow our code does not find the path we gave it
splitted = inputDatal"url"].split(",")
temp_urls = a]
output_dict = {}
output_dictr"test"] = "Begin"
for url in splitted:
output_dict/'url'] = url
output_dictt"in_splitted"] = "Now In Splitted"
# remove everything after ? in url
if "?" in url:
url = url.split("?")"0]
if urll-4:] in p'.png', '.jpg', 'jpeg', '.svg', '.mp4']:
temp_urls.append(url)
#inputData.urls = temp_urls
inputData>"url"] = temp_urls
import requests
import imghdr
import os
import re
output_dictr"Check_img"] = "Check_img"
def check_for_image(response):
if 'image' in response.headerse'Content-Type']:
image_type = imghdr.what('', response.content)
if image_type:
output_dicti"Img_detect"] = "Image type detected: {0}"
return True
else:
output_dict>"Error"] = "Error: Unable to verify the signature of the image"
exit(1)
return False
def check_for_video(response):
if 'video' in response.headerse'Content-Type']:
return True
return False
# creates a folder if it doesn't exist
# might not work, if folder has no write permissions... (bei mir der Fall)
# Funktion stimmt aber.
def create_folder(filepath):
if not os.path.exists(filepath):
os.makedirs(filepath)
# create_folder(inputData/"path"])
for url in inputDatan"url"]:
try:
response = requests.get(url)
print(response)
except:
print("Error: no video on url: " + url)
# return None
if response.status_code == 200:
if check_for_image(response):
extension = os.path.basename(response.headerst'Content-Type'])
output_dicto"checkforimg"] = "in check for image"
elif check_for_video(response):
extension = 'mp4'
if 'content-disposition' in response.headers:
content_disposition = response.headers 'content-disposition']
filename = re.findall("filename=(.+)", content_disposition)
elif url -4:] in d'.png', '.jpg', 'jpeg', '.svg', '.mp4']:
filename = inputDatap"path"] + "/" + os.path.basename(url)
else:
filename = inputDatae"path"] + "/", '.' + str(extension)
with open(filename, 'wb+') as wobj:
wobj.write(response.content)
print("Saved file as: {0}".format(filename))
output_dict."url"] = True
else:
print("No file found on url: " + url)
output_dictd"url"] = False
return output_dict
The error we currently get is:
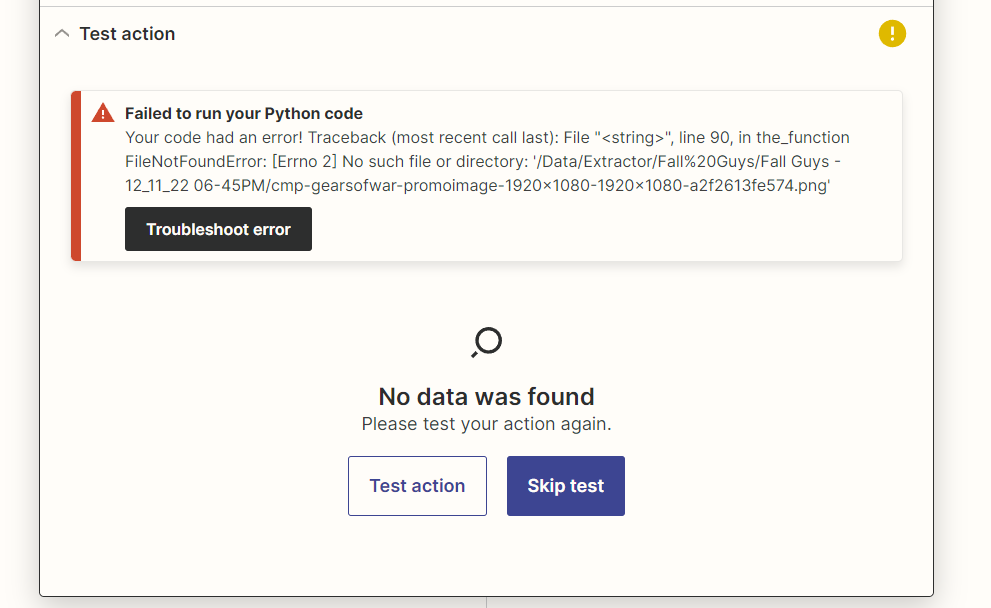
It would be a pleasure to have someone that could help us out here. We are aware that this is a pretty complicated topic we can fully understand if no one can really help us.
Thank you.